
Enterprise AI Weekly #4
The world continues to go agent crazy with Manus, Sesame bridges the uncanny valley, Google is still flying high, Mistral shows up for Europe and AI gets creative with writing both fiction and music.

Welcome to Enterprise AI Weekly #4
Welcome to the Enterprise AI Weekly Substack, published by me, Paul O'Brien, Group Chief AI Officer and Global Solutions CTO at Davies.
Enterprise AI Weekly is a short-ish, accessible read, covering AI topics relevant to business of all sizes. It aims to be an AI explainer, a route into goings-on in AI in the world at large, and a way to understand the potential impacts of those developments on your business.
If you’re reading this for the first time, you can read previous posts at the Enterprise AI Weekly Substack page.
Finally, I have also created a Teams channel to discuss topics mentioned in this post, and AI in general, with your fellow readers, and of course me too. To join, use this link. I’ll also post the things that made my Pocket list, but didn’t make it to the post!

Explainer: Guardrails
As we continue to harness the power of generative AI, we have a responsibility to ensure that it is used safely and responsibly. To do this, we need to implement guardrails. As the name suggests, these serve as essential guidelines that shape the behavior of AI models, allowing organisations to build generative capabilities on a foundation of trust. By implementing these safeguards, we can mitigate risks such as security breaches, compliance violations, and ethical concerns while still leveraging the potential of this transformative technology.
Guardrails in AI applications encompass a range of frameworks, processes, and tools designed to monitor and regulate system behavior. From a technical perspective, they can proactively prevent unintended or harmful outcomes by blocking malicious inputs (for example, prompts specifically crafted to encourage the AI to act outside of its normal behaviour, often referred to as ‘jailbreaks’), filtering false outputs (hallucinations), detecting vulnerabilities, and protecting sensitive data. Some organisations implement their own prompt engineering to guide AI models towards desirable outputs, while others use “LLM as a judge” systems to evaluate output compliance with predefined rules.
As systems become more agentic in nature and therefore have increased autonomy, guardrails with human involvement become even more important - escalation protocols to automatically route complex/unusual cases to humans, a human approval process for high-stakes decisions and real-time monitoring via dashboards providing tracking metrics like bias scores or compliance violations.
As businesses implement Generative AI, guardrails are of paramount importance. They not only mitigate risks associated with AI deployment but also foster trust and ensure responsible innovation. Across the business, we are working closely with Microsoft and deploying Generative AI using the Azure AI Foundry. Microsoft provides a service called ‘Azure AI Content Safety’ with standardised, robust guardrails, which serve as a great starting point to our overall approach to guardrail use.

1. The agentic buzz continues for Manus and OpenAI
AI agents are hitting the headlines again this week with the launch of Manus, a groundbreaking autonomous AI agent developed by Chinese startup Butterfly Effect. Unveiled on 6th March, Manus represents another leap forward in AI technology, moving beyond traditional chatbots to become a fully autonomous digital assistant capable of planning and executing complex tasks with minimal human input.
Manus operates using a multi-agent architecture, functioning like an executive managing a team of specialised sub-agents. It can break down complex tasks, assign them to appropriate agents, and monitor their progress in real-time. This allows Manus to handle a wide range of tasks, from analysing financial data and creating personalised travel itineraries to building websites and automating marketing processes. The AI community has responded with excitement, with some hailing it as China's "second DeepSeek moment" and potentially the world's first human-level AI (it’s not). However, early users have reported some issues with system crashes and instability, indicating that while promising, Manus is still a work in progress. Scarcity of actual access to the platform and an ‘invite system’ with a huge waitlist is partly helping to fuel excitement about the platform. Unsurprisingly, the release has already spawned a number of Open Source competitors, including Owl, and, er, ANUS. 🤦♂️
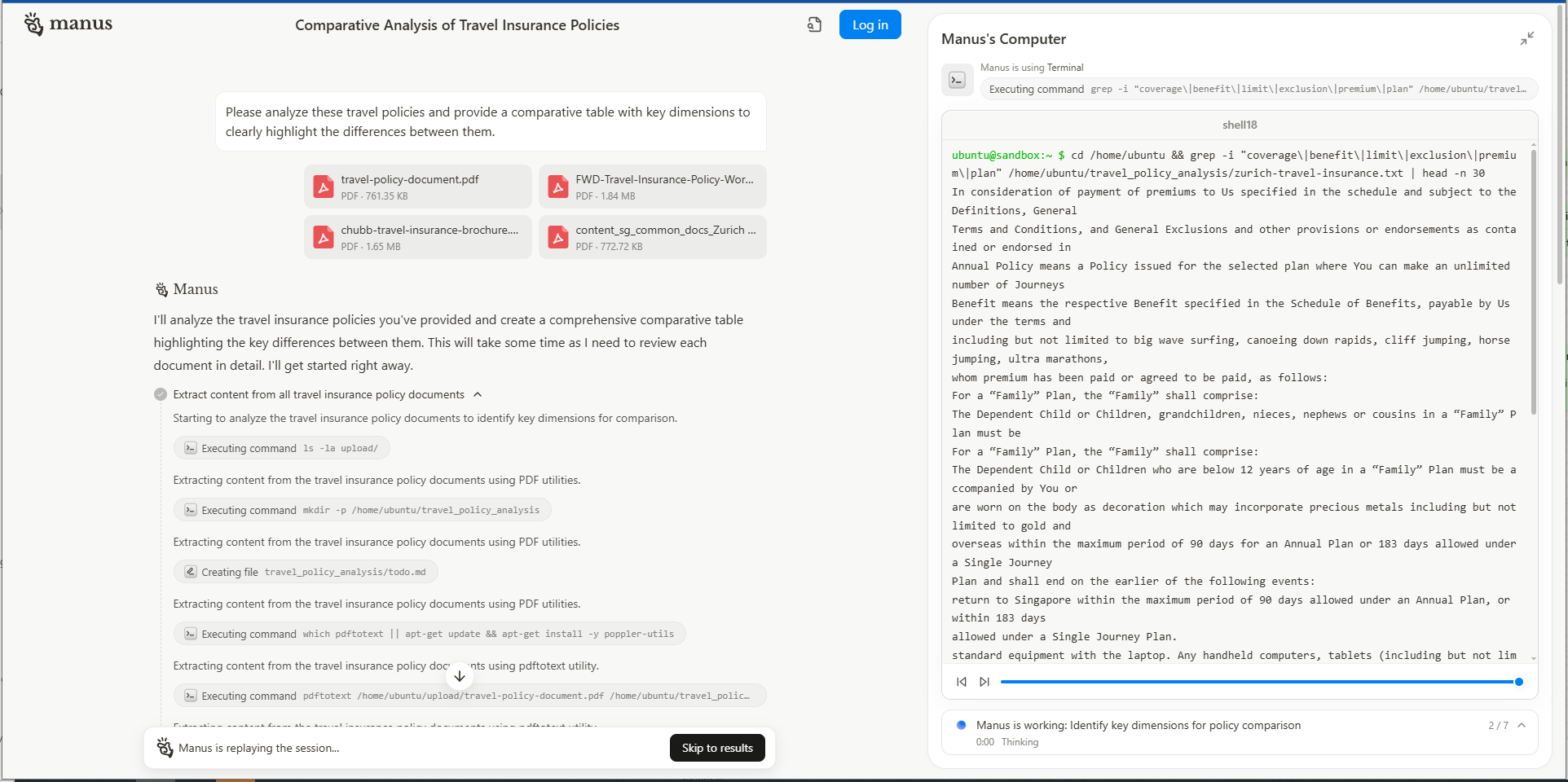
The announcement of Manus has highlighted the potential of CUA technology (‘Computer Use Agent’) and while initial experiences of OpenAI’s Operator have proven less than impressive, capabilities are ramping up fast. Manus is built on the ‘browser use’ open-source library, designed to make websites accessible to LLMs, which itself has blown up in popularity this week. You can try a CUA for yourself with this implementation at Browserbase.
In yet another ‘OpenAI in danger of getting lost in the noise’ moment, this week also saw the release of new tools for building agents from OpenAI. The new set of APIs and tools, specifically designed to simplify the development of agentic applications, include the new Responses API, combining the simplicity of the Chat Completions API with the tool use capabilities of the Assistants API for building agents, built-in tools including web search, file search, and computer use, the new Agents SDK to orchestrate single-agent and multi-agent workflows and integrated observability tools to trace and inspect agent workflow execution. These new tools ‘streamline core agent logic, orchestration, and interactions, making it significantly easier for developers to get started with building agents’. One interesting thing to note is that the OpenAI system is geared towards Python development, which feels a little at odds with the way the space has been heading in recent months.
As we move towards an agentic future in business systems, these tools will be invaluable and will invariably mature quickly. While the ideal scenario for agentic use is via APIs or MCP, the rapidly improving ability to build solutions using web browser or computer control could be useful in specific scenarios.

2. Sesame is crossing the uncanny valley of voice
AI startup Sesame has recently unveiled a groundbreaking voice assistant that's causing quite a stir. Their Conversational Speech Model (CSM) incorporates subtle human-like elements such as micro-pauses, emphasis variations, and even laughter, making interactions feel remarkably authentic. Early testers have reported being genuinely startled by how human-like the conversations feel, with some even experiencing emotional connections to the AI voices. This level of realism represents a significant leap forward in AI voice technology, potentially revolutionising fields like customer service, digital assistants, and AI companionship.
Sesame says it is ‘aiming to achieve “voice presence” - the magical quality that makes spoken interactions feel real, understood, and valued’ and ‘creating conversational partners that do not just process requests; they engage in genuine dialogue that builds confidence and trust over time.’
The model’s ability to "cross the uncanny valley" is particularly noteworthy. The uncanny valley refers to the phenomenon where human-like entities that are almost, but not quite, human-like can evoke feelings of unease. By incorporating deliberate imperfections and human-like behaviors, Sesame's AI appears to have successfully navigated this challenge, creating a voice assistant that feels natural and engaging rather than unsettling. This achievement could be a game-changer for human-AI interactions, potentially leading to wider acceptance and integration of AI assistants in various aspects of our daily lives. As AI continues to advance, successfully crossing the uncanny valley may become crucial in developing AI systems that can seamlessly interact with humans in more complex and nuanced ways.
Intrigued? Sesame has a demo page where you can try the model out for yourself with a real-time conversation. Let us know what you think!
When we consider AI first automation, there will clearly still be a need to interact with humans. We talked in EAW #3 about how LLM performance will reach a level to provide real time conversation, and engaging, human like speech models have the potential to be another vital component in the process.

3. Google delivers again with Gemma and Flash
I need to be a bit careful not to sound like a Google fanboy with their regular appearances in the post, but they keep smashing it out of the park!
Google has just unveiled Gemma 3, the latest iteration of its open-source AI model family. This release marks a significant leap forward in democratising advanced AI capabilities. Gemma 3 is built on the same technology powering Google's flagship Gemini 2.0 models, offering state-of-the-art performance in a lightweight, accessible package.
Gemma 3's standout features include multimodal capabilities, allowing it to process both text and images, a generous context window of up to 128,000 tokens, and support for over 140 languages. Available in sizes ranging from one billion to twenty-seven billion parameters, Gemma 3 is designed to run efficiently on various devices, from smartphones to workstations (you can run it locally on your PC with LM Studio). This flexibility makes it an ideal choice for developers looking to integrate advanced AI into their applications without the need for extensive computational resources.
This week, Google has also introduced Gemini 2.0 Flash Experimental, an advanced proprietary model and an evolution of the release version I raved about in EAW #1. The updated model, previously limited to trusted testers, can now be accessed using an experimental version of Gemini 2.0 Flash (gemini-2.0-flash-exp) in Google AI Studio and via the Gemini API (if you’ve not tried the studio already, I highly recommend checking it out).
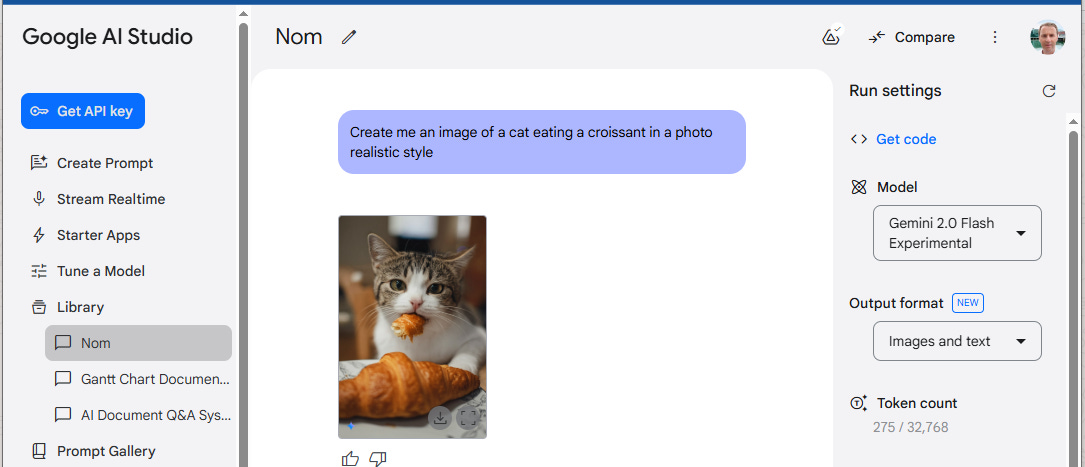
The updated model includes native image generation and combines multimodal input, enhanced reasoning, and natural language understanding to create images that precisely match user requests. It excels in various applications, including storytelling with consistent character and setting illustrations, conversational image editing through natural language dialogue, and creating detailed, realistic imagery based on world knowledge. One of its standout features is the ability to accurately render long sequences of text within images, outperforming leading competitive models in internal benchmarks. This makes it particularly useful for creating advertisements, social media posts, and invitations with clear, legible text.
So why Gemma and Gemini? The key difference between Gemma and Gemini lies in their accessibility and intended use cases. Gemma, being open-source, offers developers and researchers the freedom to experiment, modify, and integrate the model into their projects with fewer restrictions. It's ideal for those looking to build custom AI solutions or contribute to the advancement of AI technology.
Gemini, on the other hand, is a proprietary model designed for advanced AI research and large-scale applications. It offers more sophisticated capabilities and is better suited for complex tasks that require significant computational power. Gemini is typically accessed through Google's ecosystem, making it a good choice for enterprises looking for a ready-to-use, powerful AI solution.
As before, the rapid advances in Gemini show that we mustn’t count Google out as a player in the AI space. The Gemini 2.0 Flash is a low cost model that continues to get rave reviews, and the multimodal and thinking experimental versions are also impressive. We have an existing relationship with Google through our Vertex AI work in DTS, which we will look to expand.

4. Mistral flies the flag for Europe with its OCR release
In a landscape dominated by Silicon Valley giants, Mistral AI stands out as a European powerhouse in the artificial intelligence arena. Founded in Paris in 2023 by alumni from Meta and DeepMind, Mistral has quickly risen to prominence, raising over €1 billion in less than a year and achieving a valuation of €5.8 billion - the highest for an AI startup in Europe. The company's mission is to create a strong European presence in AI, competing directly with US-based tech giants while maintaining its independence.
Mistral has recently unveiled its latest innovation: Mistral OCR, an advanced Optical Character Recognition API that promises to revolutionise document processing. This new offering boasts impressive capabilities, processing up to 2,000 pages per minute on a single node - outpacing competitors like Google Document AI and Microsoft Azure OCR. What sets Mistral OCR apart is its multimodal approach, accurately recognising and processing not just text, but also images, tables, equations, and even handwritten notes. The API supports hundreds of languages across different writing systems and excels in extracting complex elements like LaTeX formatting.

For businesses dealing with vast document repositories, Mistral OCR offers a game-changing solution. It can convert unstructured PDFs and images into AI-ready formats like Markdown or JSON, making it particularly useful for Retrieval-Augmented Generation (RAG) systems. The API's 'document-as-prompt' feature allows for extraction of specific information and formatting into structured outputs, seamlessly integrating with AI agents, automation tools, and search systems. With its self-hosting capability for organisations with strict security requirements and its competitive pricing of 1,000 pages per dollar, Mistral OCR is poised to transform how companies handle document processing across various industries, from legal and compliance to scientific research and customer service.
We know that documents are key to so much of what we do, so the release of an advanced new model is a significant moment. We could potentially use it in our solutions (I expect it to become available in Azure AI Foundry), and once again it’s driving the cost of these kinds of solutions down.

5. Can AI genuinely be creative?
Can AI genuinely be creative? Quite the rabbit hole that one, but there’s clearly something there given Christie’s recent AI art sale outpaced expectations and raised $728,000. AI art is highly controversial, given the argument that everything created by a trained model is derivative. And yet, as we learn, is our work as humans derivative too? Let’s not go there. A couple of interesting things in this space caught my eye this week.
NotaGen, an open-source music generation model, has recently made waves in the AI and music communities. This innovative system uses training paradigms similar to large language models, pre-trained on an impressive 1.6 million musical works. NotaGen specialises in generating high-quality classical music but also supports pop music creation, showcasing AI's versatility in musical composition.
The model's strength lies in its controllability and professionalism. Users can specify musical period styles (Baroque, Classical, or Romantic) and instrument types to generate tailored scores. NotaGen was fine-tuned on a dataset of 8,948 classical scores from 152 composers, resulting in outputs that closely match professional composition standards. The recent open-sourcing of NotaGen, including an enhanced version called NotaGen-X, has made this powerful tool accessible to music enthusiasts, developers, and researchers worldwide. Check out the demos on YouTube.

In an unexpected development, OpenAI CEO Sam Altman revealed on X that the company has trained a new AI model specifically for creative writing. Altman shared a sample story generated by the model, describing it as the first time he's been "really struck" by AI-generated writing. The model was given a prompt to author a short story about AI and grief, producing a 1,172-word piece that explores the concept of an AI chatbot simulating conversations with a lost loved one.
While Altman expressed enthusiasm about the model's capabilities, reactions have been mixed. Some praise the AI's ability to capture the essence of metafiction, while others question the depth and emotional resonance of AI-generated literature. The release date and specifics of this new model remain uncertain, but its development signals OpenAI's expanding interest in creative applications of artificial intelligence.

POB’s closing thought(s)
When I first thought about this post concept, my main concern was that there would not be enough to talk about. Now my main concern is what to leave out because so much has happened in a week (you can see the things that didn’t make the cut in the Teams chat). Such is the pace of change.
I’ll wrap up this week with a mention for one of my favourite AI tools, NotebookLM. Argh, I just noticed it’s another Google product in the post, hah! NotebookLM is an AI-powered tool developed by Google that acts as a personalised research assistant, allowing users to upload documents and interact with them through summaries, questions, and content creation, all grounded in the specific sources provided. It works amazingly well and is incredibly useful. Its real party piece is that it can create podcasts based on the information you upload. No matter how inane your topic, you can get two excitable podcasters chatting about your materials, perfect for a slightly unusual way to consume boring documents. Try it… then check out this X post for how AI is taking things to the next level with generated video.
Until next time… enjoy the rest of your week! 👍
Disclaimer: The views and opinions expressed in this post are my own and do not necessarily reflect those of my employer.