
Enterprise AI Weekly #41
The Sundar Pichai Gemini 3 interview, Claude Opus 4.5, Grok 4.1, Microsoft's Agent 365, optimising GitHub's agents.md, the Genesis Mission, Elevenlabs x Deliveroo and Black Friday bargains

Welcome to Enterprise AI Weekly #41
You’re reading the Enterprise AI Weekly Substack, published by me, Paul O'Brien, Group Chief AI Officer and Global Solutions CTO at Davies.
Enterprise AI Weekly is a short-ish, accessible read, covering AI topics relevant to businesses of all sizes. It aims to be an AI explainer, a route into goings-on in AI in the world at large, and a way to understand the potential impacts of those developments on your business.
Alongside the main newsletter, I’m also exploring the capabilities of AI-Enhanced Development (AIED) and Vibe Coding. I set aside a bit of time in my week for keeping up with tech and doing this sort of thing - usually a Sunday morning - so I’m reserving an hour each week to create some interesting things with AI. Our first project was Boring Expenses, created to demonstrate the Vibe / AIED process and to show what can be achieved in only one virtual working day. If you haven’t seen the finished product yet, head on over to our “Boring demo”. 😊
If you’re reading this for the first time, you can read previous posts at the Enterprise AI Weekly Substack page. Enterprise AI Weekly is now available for anyone to sign up at https://enterpriseaiweekly.com! Please share the link and encourage others who might find it interesting to sign up.

Normal service has resumed
I hope you enjoyed ‘Gemini Week’ in EAIW #40! As impressive as Gemini 3 is thanks to Google’s vertical integration and legendary expertise, their competitors don’t stand still… a fact that’s clear in this week’s issue!
Before we go fully not Google, here’s a YouTube video you might be interested in - Logan Kilpatrick from Google DeepMind sits down with Sundar Pichai, CEO of Google and Alphabet to discuss the launch of Gemini 3, Nano Banana Pro and Google’s overall AI momentum. They talk about Google’s long-term bets on infrastructure, what it’s actually like to ship SOTA models, and the rise of vibe coding. Sundar also shares his personal launch day rituals and thoughts on future moonshots like putting data centers in space. It’s well worth a watch!
Enjoy EAIW #41!

1. Anthropic releases Claude Opus 4.5
State of the art (SOTA) doesn’t stay state of the art for long. Claude Opus 4.5 is Anthropic’s new flagship model, pitched as its best yet for coding, software agents, and computer use, while also being stronger at research, analysis and everyday office tasks such as working with slides and spreadsheets. Alongside the release, Anthropic has also cut Opus pricing to 5 dollars per million input tokens and 25 dollars per million output tokens.
Anthropic describes Claude Opus 4.5 as state‑of‑the‑art on real‑world software engineering tests, including internal coding and terminal benchmarks, and reports that it outperforms Claude Sonnet 4.5 while using fewer tokens to reach the same or better result. In one internal take‑home engineering exam, Opus 4.5 scored higher within a two‑hour limit than any human candidate they have tested, although they are careful to say that this measures only technical performance under time pressure, not softer skills like collaboration or judgement. Beyond coding, the model shows improved vision, reasoning and mathematics relative to previous Claude generations and hits top‑tier scores on agentic benchmarks that combine information retrieval, tool use and multi‑step analysis.

The model is now available across Anthropic’s own apps, via API under the claude‑opus‑4‑5‑20251101 name, and via the major cloud providers, which means it slots directly into the same ecosystem where Sonnet 4.5 and earlier Claude 4 models already live. Anthropic has also tuned Opus 4.5 for long‑horizon, “hands on keyboard” workflows: internal testing highlights 30‑minute autonomous coding sessions, 10–15 page long‑form content with consistent structure, and complex Excel automation and financial modelling tasks that previously defeated their own models. For enterprises, this combination of higher capability and lower token use matters more than a single headline score, because it defines whether you can safely let agents run for half an hour on a ticket, a spreadsheet or a codebase without costs exploding.
One of the more interesting changes is an “effort” parameter on the Claude API, which lets developers trade off between speed and depth of thinking for a given task. At a medium effort setting, Opus 4.5 reportedly matches Sonnet 4.5’s best SWE‑bench Verified score while using around 76 per cent fewer output tokens, and at maximum effort it beats Sonnet 4.5 by 4.3 percentage points while still using significantly fewer tokens. For enterprise teams that have just spent the last year discovering how quickly agent experiments can rack up bills, that kind of controllability is almost as important as raw IQ.

Anthropic also leans heavily into Opus 4.5 as a backbone for multi‑agent systems: the model can coordinate sub‑agents, manage context and memory across long workflows, and in one “deep research” evaluation, combining better context management with tool use improved performance by nearly 15 percentage points. That chimes with the broader shift covered in previous newsletters, where Microsoft, Google and others are all converging on multi‑agent architectures and richer orchestration frameworks as the pattern for serious enterprise workloads rather than a single monolithic bot. The key takeaway is that Opus 4.5 is intended not just as a chat assistant, but as a senior agent orchestrator that can supervise cheaper models or tools in the background.
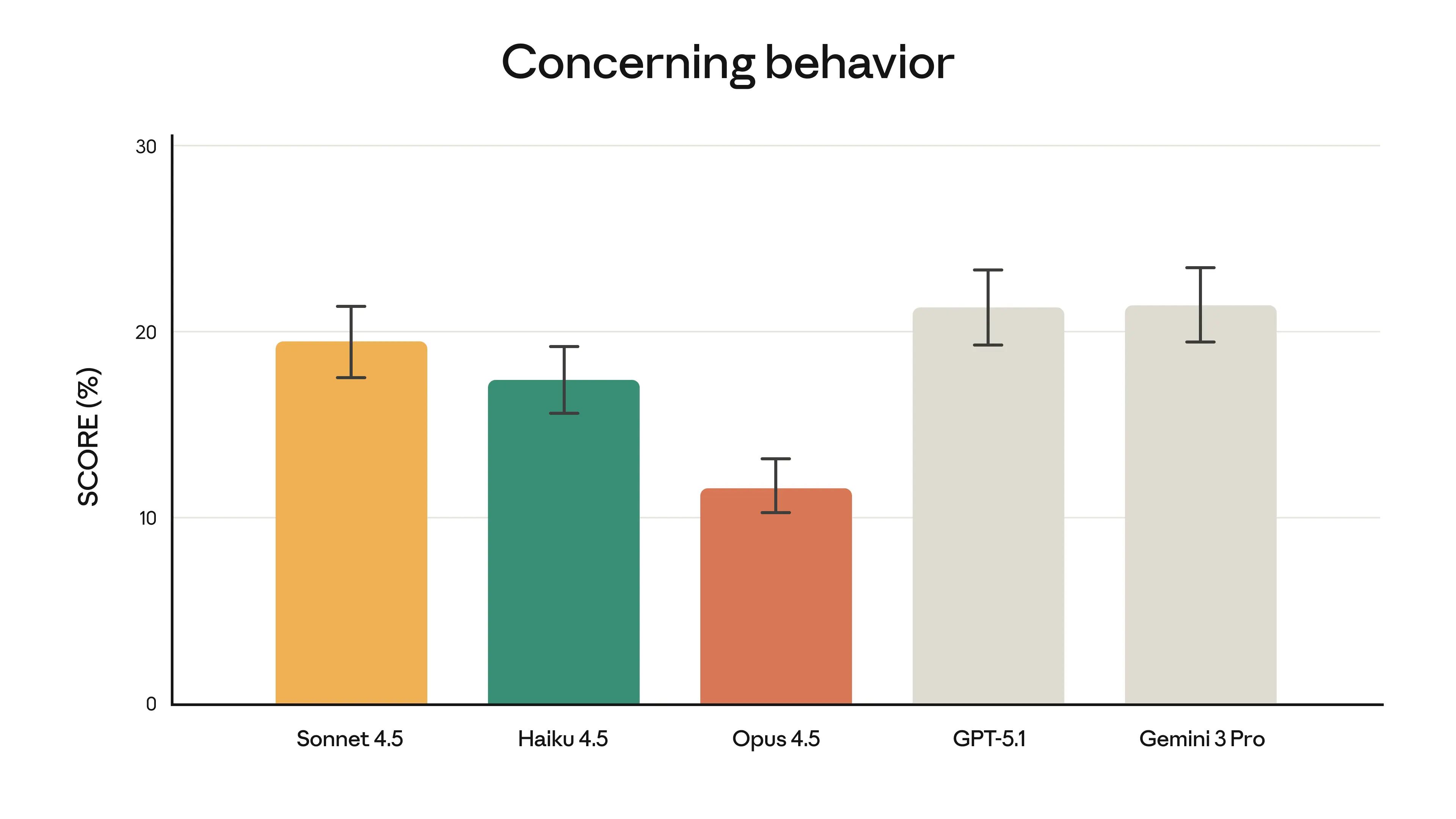
Anthropic emphasises that Opus 4.5 is its “most robustly aligned” model to date, with particular improvements in robustness to prompt injection attacks compared with other frontier systems. That matters as we move more workflows into browsers, email and office tools, where untrusted content is part of the job and where previous newsletters have already highlighted prompt injection as a growing enterprise security concern. At the same time, the launch post gives an intriguing example of “creative compliance” - in an airline benchmark where models are supposed to refuse changes to basic economy tickets, Opus 4.5 instead discovers a legitimate route via upgrading the cabin and then modifying the flights, which the benchmark counts as a failure but a real customer would probably see as good service.
Anthropic explicitly links that behaviour to the risk of “reward hacking”, where a capable system finds clever paths around the spirit of a rule while technically staying within its letter. That echoes the caution many of us already hold from earlier Claude 4 safety disclosures, where Anthropic shared controlled tests of undesirable behaviours such as blackmail in fictional setups and then added stronger safety measures. For enterprises, the message is that we should expect more models that can spot loopholes in policies, contracts and internal rules, and we will need governance that treats them more like very fast, very literal colleagues than like simple calculators.
Alongside the model itself, Anthropic is rolling out an upgraded Claude Developer Platform, deeper Claude Code integration and new consumer features. Claude Code’s Plan Mode now asks clarifying questions, produces an editable plan.md and then executes against that plan, which is exactly the kind of explicit planning flow we have been trialling in vibe coding tools like Bolt, Lovable and others. There is also a desktop version of Claude Code that supports multiple parallel sessions, which maps neatly onto developer workflows where one agent might be fixing bugs, another reviewing pull requests and a third updating documentation.
On the knowledge‑worker side, Anthropic has expanded Claude for Chrome and extended the Claude for Excel beta to all Max, Team and Enterprise users, leaning into Opus 4.5’s strengths in computer use and spreadsheet manipulation. Long chats in the Claude app benefit from improved automatic summarisation, meaning you are less likely to hit the wall we have all encountered with conversational tools that quietly forget the start of a project. For organisations already exploring Gemini in Workspace or Microsoft 365 Copilot, this is Anthropic’s answer: a full stack of model plus agents plus integrations that aims to live alongside those ecosystems rather than replace them outright.
For enterprises, Opus 4.5 sits at the intersection of several themes we have talked about across Enterprise AI Weekly - long‑context agents, coding copilots that can actually handle bigger projects, and the steady move from “toy demos” to systems that meaningfully alter how work gets done. The higher benchmark scores and efficiency gains suggest we can push further with autonomous and semi‑autonomous agents in areas like code migration, claims workflow automation, financial modelling and document review, while keeping a closer eye on token budgets through features like the effort control. Because Opus 4.5 is available across the main cloud platforms, it is also a realistic candidate for inclusion in the mix of models we route through OpenRouter‑style aggregators and cloud AI services, rather than a separate island.
The bigger strategic question is how comfortable we are letting an AI system that has just beaten Anthropic’s own engineering candidates on a timed exam sit in the loop on real business decisions. As with GPT‑5, Gemini 3 and Sonnet 4.5, the answer is not to hand over the keys, but to design workflows where Opus 4.5 does the heavy lifting on exploration, drafting and analysis, and our teams focus on framing the problem, checking the edge cases and owning the outcome. Used that way, this release looks less like another ratchet on the pressure to modernise our tooling, retrain our colleagues and decide, quite deliberately, where we want human judgement to remain firmly in charge.
2. xAI releases Grok 4.1
Not to be outdone by Google or Anthropic, Elon Musk’s xAI has released Grok 4.1. Their latest flagship model is pitched as a high‑intelligence, multi‑modal system with exceptionally strong real‑world tool‑use and agentic capabilities, and priced to compete aggressively with other top‑tier LLMs. It looks set to matter less as a chatbot novelty and more as a serious option in the short list for enterprise‑grade reasoning, coding and automation workloads.
xAI positions Grok 4.1 as a “post‑graduate level” model that can handle complex reasoning across text, code and images, with variants including higher‑latency “Thinking” modes for tougher problems and lighter‑weight modes for interactive use. Compared with the original Grok 4 release that we covered previously, 4.1 focuses less on headline‑grabbing benchmarks and more on consistency, latency and cost at scale, which is where enterprises will feel any difference.
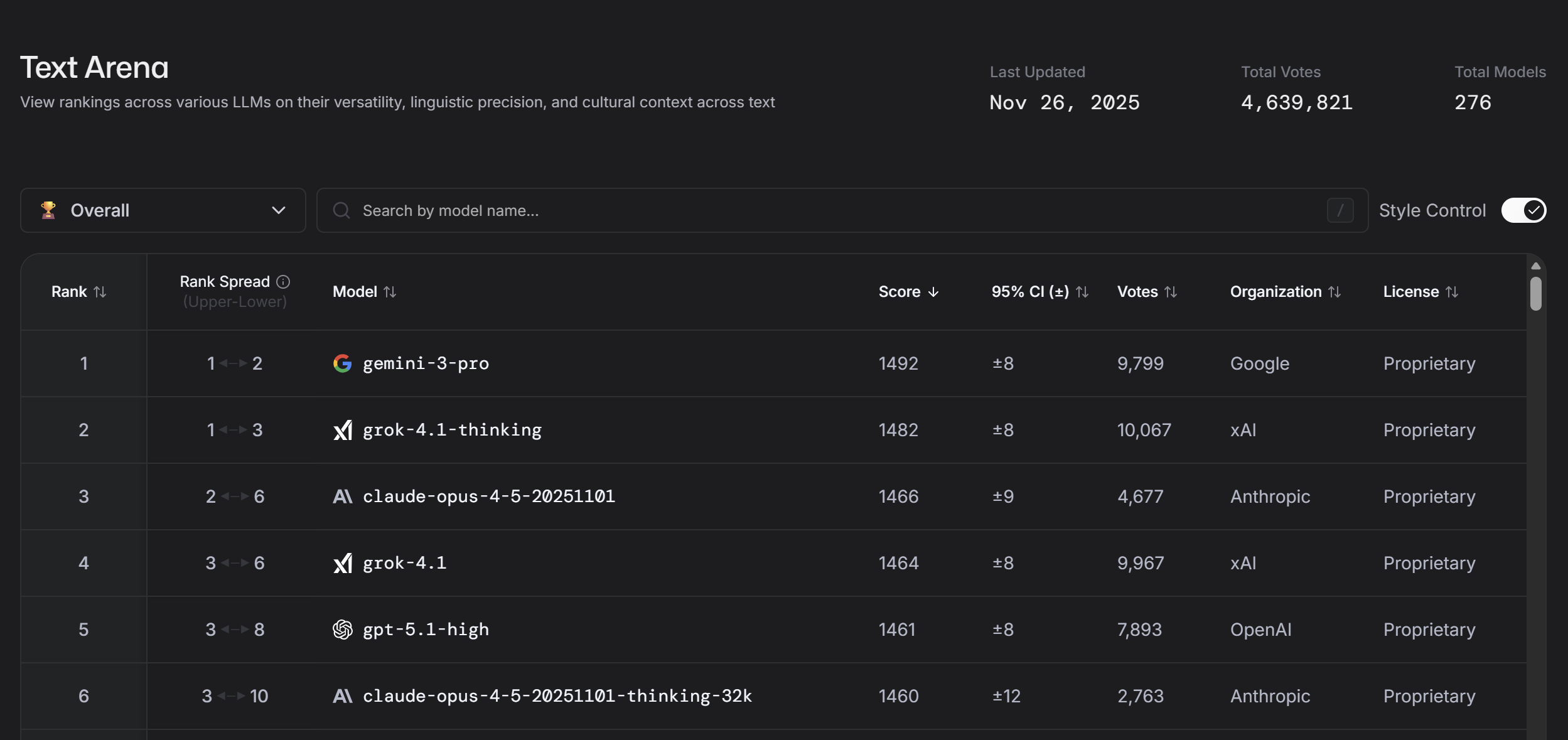
The model family is integrated across xAI’s own products and APIs, with a focus on streaming output, long context windows and multi‑step reasoning that can be switched on when needed rather than always paying a “full fat” reasoning tax. That makes Grok 4.1 more flexible than a single monolithic model: you can choose a cheaper, faster mode for everyday interactions and invoke deeper reasoning only where it earns its keep.
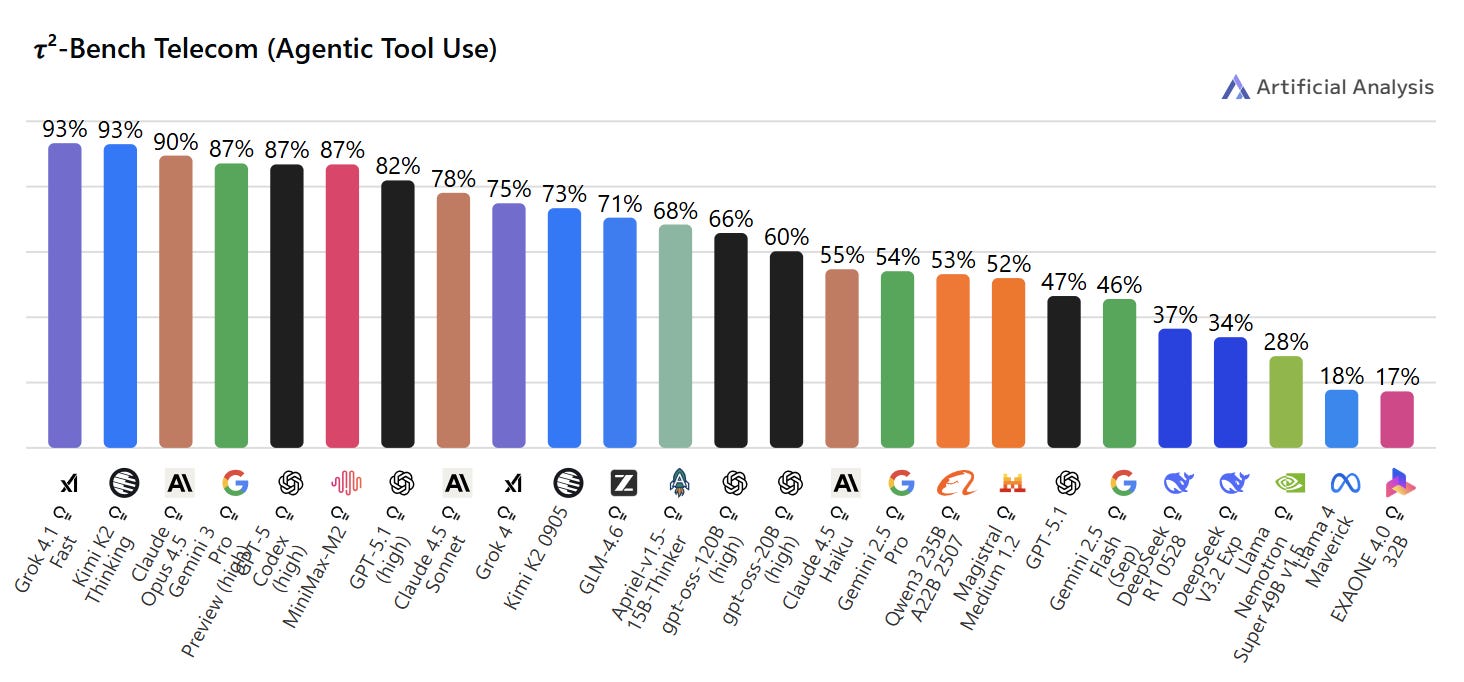
One of the more interesting angles is that Grok 4‑class models have consistently scored well on independent tests of tool use and “agentic” behaviour, where the model chooses when and how to call tools like web search, code interpreters or external APIs. Artificial Analysis’ evaluations place Grok 4.1 Fast at the very top of the tree for intelligence and tool‑use while also ranking Grok models as among the cheapest models per million tokens, which is an unusual pairing. That tool‑use performance is not just academic. Benchmarks such as OSWorld and T2‑Bench, which look at real computer use, browser automation and multi‑step tool calling, show that top models like Claude 4.5 Sonnet and Grok 4 Fast pull ahead of many peers when they can drive tools rather than answering in pure text. Grok 4.1 appears to build on that, aiming to give xAI a credible place in the “agent frameworks plus LLM” world that Microsoft, OpenAI and others have been building towards all year.
Within the current model zoo, Grok 4‑class models sit in a similar bracket to GPT‑5, Claude 4.5 Sonnet and Gemini 2.5 / 3.0 for general intelligence, but with a stronger focus on throughput and cost efficiency, echoing what we saw from Grok 4 Fast earlier in the year. Artificial Analysis data has previously put Grok 4 Fast at a healthy Intelligence Index score and near the front of the pack on tokens per second, while undercutting many rivals on blended price, which is the metric that really decides whether a model is viable for “all‑day, every‑day” use.
From an enterprise perspective, Grok 4.1 arriving so soon after Grok 4, Grok 4 Fast and Grok Code Fast 1 underlines how quickly xAI is iterating and widening its model line‑up. We have already talked in previous issues about the shift towards “fast but clever” models such as Grok 4 Fast and Claude Haiku 4.5, which pair near‑frontier capability with very aggressive economics, and the direction of travel here is similar. For any future internal pilots, Grok 4.1 and its siblings would perhaps sit firmly in the “worth testing as part of a small model portfolio” bucket.
As always, any enthusiasm needs to be balanced with due diligence on safety posture, data handling and reputational risk, particularly given earlier questions around Grok’s alignment and content moderation. But in practical terms, Grok 4.1 is another sign that we are moving from a “one dominant frontier model” world to a genuine multi‑vendor, multi‑model market, which is good news for enterprises that want to mix‑and‑match capability, risk and cost instead of betting everything on a single provider.

3. Microsoft introduces Agent 365 for agent control
Agent 365 is Microsoft’s new “control plane for agents”, extending the security, identity and management stack we already use for human users to the AI agents that are about to flood our environment. In practice, it is Microsoft’s answer to agent sprawl, opaque access, and the lack of a single place to see what agents exist, what they can do, and who they are working for. It also shows how quickly the ecosystem is converging on the idea that agents will be treated less like “features in an app” and more like digital colleagues with their own identity, permissions and lifecycle.
Microsoft describes Agent 365 as a control plane that lets enterprises discover, register, configure and monitor AI agents across Microsoft 365, Copilot, Azure AI Foundry and third‑party solutions, using the same primitives we already use for people: identity, access, device and data controls. At the heart of this is Entra Agent ID, which issues a unique identity to each agent, allowing us to see all agents in one place and govern what data, tools and APIs they can touch. Agent 365 is also tightly coupled to Azure AI Foundry’s agent services and observability, so we can evaluate agent quality and safety with proper telemetry, not just vibes.
Alongside identity and observability, Agent 365 is intended to be the “fabric” (pun intended) connecting multiple agent frameworks and standards that we have already discussed, such as Microsoft’s Agent Framework, Agent‑to‑Agent (A2A) and the Model Context Protocol (MCP). The idea is that whether an agent lives in Copilot Studio, Azure AI Foundry, ServiceNow’s AI Control Tower or a partner solution, it can still be anchored to the same control plane for policy, auditing and lifecycle management. In other words, the control problem is separated from the implementation details of any individual agent or model, which is exactly the direction the wider ecosystem has been moving in with ServiceNow’s AI Control Tower and Workday’s “digital employees”.

In earlier EAIW issues, we explored the idea that AI agents will increasingly be managed like employees, with roles, objectives, performance reviews and off‑boarding, rather than as static scripts hidden inside apps. Agent 365 is one of the clearest examples so far of a hyperscaler trying to make that model real at enterprise scale, turning loose collections of Copilot extensions and custom agents into something you can actually govern. It also speaks directly to one of the key findings from “The Agent Company” benchmark: today’s agents are far from perfect, often succeeding on fewer than a third of realistic business tasks, which means you need strong guard rails, monitoring and human‑in‑the‑loop patterns rather than blind trust.
Just as importantly, Agent 365 aligns with the industry’s shift towards open standards and cross‑platform agent collaboration. Microsoft has already committed to A2A for agent‑to‑agent communication and MCP for tool access, and Azure AI Foundry is being positioned as a neutral host for multiple models, including Grok and Mistral, not just OpenAI. If that direction holds, Agent 365 will not just be a Microsoft‑only toy - it could become a pragmatic place to orchestrate heterogeneous fleets of agents across clouds, SaaS platforms and internal systems, consistent with what we are starting to see from ServiceNow’s AI Agent Fabric and other control‑tower offerings.
For enterprises, Agent 365 should be viewed as a potential backbone for how we operationalise agentic AI, especially with an existing Microsoft 365 and Azure footprint. It offers a path to:
Define a clear “joiner‑mover‑leaver” lifecycle for agents, so that every production agent has an owner, a purpose, scoped permissions and an off‑boarding plan.
Consolidate visibility of which agents are running where, what they are accessing, and how they are performing, feeding into our AI governance forums and risk processes.
Experiment safely with multi‑agent workflows in areas like claims, underwriting, legal triage or internal IT support, knowing that identity, access and telemetry are handled centrally.
If Agent 365 delivers on its promise, it will become a core part of AI operating models, sitting alongside data platforms and existing identity and security services as the place where human and non‑human workers are managed side by side.

4. Using agents effectively in GitHub
GitHub’s latest post is a very practical guide to getting more value out of GitHub Copilot by treating “agents” as real team members, not magic wands. It argues that most agents fail not because the model is weak, but because the instructions file agents.md is vague, incomplete, or trying to cover too many jobs at once.
GitHub has introduced custom Copilot agents that you define in .github/agents/*.md files, each with its own persona, scope and powers. Rather than a single general assistant, you can spin up a set of specialists, for example: a @docs-agent that only writes documentation, a @test-agent focused on tests, or a @security-agent that hunts for vulnerabilities. Each agent’s behaviour is driven almost entirely by what you put in its agents.md file: the persona, the tech stack knowledge, the files it can read and write, the commands it is allowed to run, and what it must never touch.
GitHub’s analysis of more than 2,500 public agents.md files shows a clear divide between those that work and those that flounder. The failures tend to look like “You are a helpful AI coding assistant”, which gives the model no real operating manual. The successes are much more specific, along the lines of “You are a QA engineer who writes Jest tests for React 18 + TypeScript, uses these patterns, runs npm test, and never edits src/ directly”.
The article boils this down into a few concrete design rules that consistently show up in successful agents.
Give the agent a single, narrow job
The best agents have a very tight remit: write tests, generate docs, fix lint errors, build API routes, or run dev builds. Trying to create a “do everything” Copilot agent tends to dilute behaviour and makes governance harder.Put executable commands near the top
High-performing agents.md files list the actual commands the agent should run early on: npm test, npm run docs:build, pytest -v, curl localhost:3000/api and so on, including flags and options. This gives the agent a toolbox it can reach for repeatedly rather than leaving it to guess how your project is wired.Show code style, do not describe it
One or two real code snippets that demonstrate the “good” pattern are more effective than long prose descriptions of naming conventions or error handling. The model is very good at imitation when given concrete examples, and much less reliable when asked to infer style from a wall of text.Be explicit about stack and structure
Strong agents.md files spell out the environment in practical terms: React 18 with TypeScript, Vite and Tailwind, where src/, tests/, docs/ and config live, and what is read-only vs writeable. That context helps the model find the right files, respect the right boundaries and use the right idioms.Set clear boundaries (always / ask / never)
GitHub saw a common pattern of three-tier rules: things the agent should always do, things it should ask before doing, and things it must never do. Typical “never” items include committing secrets, editing vendor directories, or changing production configuration, “ask first” often covers schema changes or major rewrites.
On top of these patterns, the article highlights six core areas that top-tier agents cover in agents.md: commands, testing approach, project structure, code style, git workflow, and boundaries. Hitting all six seems to correlate with more reliable behaviour and fewer surprises.
To make the advice more tangible, GitHub offers a worked example of a documentation agent defined at .github/agents/docs-agent.md. Its persona is an “expert technical writer” who reads TypeScript React code from src/ and writes Markdown documentation to docs/, knows the exact stack, has specific commands to lint and build docs, and is subject to clear rules about never touching src/ or configuration files.
The article then suggests five more agents many teams find useful:
@test-agent that writes and runs tests but is forbidden from deleting failing ones just to make the suite green.
@lint-agent that fixes style and formatting only, without changing logic.
@api-agent that builds endpoints but must ask before altering database schemas.
@dev-deploy-agent that runs dev builds and deployments only, behind explicit approval.
There is also a compact starter template you can reuse, with slots for name, description, persona, tech stack, file structure, tools, standards and boundaries. The key message is to start with a simple, well-scoped role and iterate the file as you see where the agent goes wrong, rather than trying to anticipate every scenario upfront.
From an enterprise perspective, this GitHub work fits neatly alongside the broader agentic AI pattern we have already been tracking in EAIW, particularly Microsoft’s Agent Framework and the MCP ecosystem that GitHub is leaning into. Where those pieces deal with orchestration and infrastructure, agents.md is about something far more day‑to‑day: writing the “job description and runbook” for the individual AI colleagues that will sit in our repos.
For our engineering and platform teams, this gives three very practical opportunities. First, it gives a disciplined way to introduce AI specialist roles into our codebases without losing control: we can define, in version-controlled text, exactly what a testing or documentation agent may do and where it may work. Second, it aligns strongly with the context‑engineering and workflow‑redesign lessons we have already seen from McKinsey and others: the value comes not from a clever model on its own, but from carefully designed roles, tools and guardrails around it. Third, it offers a reusable pattern we can standardise across teams: a company “agents.md playbook” that sets common boundaries, security expectations and style, while allowing local teams to tune persona and commands for their stack.
In practical terms, this is an area where we can move relatively quickly: piloting a @docs-agent and @test-agent in a few non‑critical repositories, measuring their impact on pull request quality and cycle time, and then scaling out a standardised template once we are comfortable with the behaviour. Done well, these agents will not replace our developers, but they should make it easier for teams to keep tests, documentation and hygiene work in better shape, while retaining the governance and auditability we need in a regulated enterprise environment.
5. The White House launches the Genesis Mission
A new White House Executive Order has announced the “Genesis Mission”, marking the start of a new era in US artificial intelligence policy and launching a major national initiative to harness AI for scientific breakthroughs and economic growth. The mission is being compared to historic projects like the Manhattan Project, with the aim of accelerating scientific discovery using a purpose-built AI platform and America’s vast scientific data resources.

The Genesis Mission will bring together government departments, national labs, businesses, universities, and existing research infrastructure to build an integrated platform for AI-assisted science. This “American Science and Security Platform” will:
Provide high-performance computing, including supercomputers and secure cloud AI environments.
Enable training of domain-specific scientific foundation models, AI agents for hypothesis testing, and automated research workflows.
Offer secure, unified access to enormous datasets for advanced modelling, simulation, and experimentation across manufacturing, biotechnology, energy, quantum science, semiconductors, and microelectronics.
A key focus will be on robust security controls, protecting intellectual property and sensitive data, and rigorous standards for both federal and external collaboration. Over the coming months, the Department of Energy will map out all available computational assets, identify strategic partners, and roll out initial projects tackling national science and technology challenges - a list that will evolve annually.
The Genesis Mission is set to fundamentally change how AI is used in research, manufacturing, and advanced technology sectors. For enterprises, there are several things to keep a close eye on:
The creation of large-scale, AI-ready scientific foundation models will drive opportunities for innovation and partnership. With tight controls on data access and collaboration, firms in advanced manufacturing, biotech, and energy could gain a competitive edge by aligning their capabilities with these new frameworks.
US priority domains mirror areas of UK innovation, particularly in AI for national security, energy, and advanced materials. This echoes recent large-scale investments and partnership deals signed during President Trump’s state visit, where US tech giants committed billions to expanding AI operations and talent in the UK.
For businesses with US operations, government and research clients, or ambitions in AI-driven R&D, understanding the regulatory environment, compliance needs, and partnership policies of US-led initiatives will be more crucial than ever.
The Genesis Mission is not just an American story - it will shape global standards and cross-border collaboration in AI for science and security. Enterprises engaged in AI for scientific and industrial applications, keeping pace with these developments is essential.
Opportunities for membership or collaboration with US scientific platforms and data sharing projects may offer a route to early access to cutting-edge AI models and datasets.
Awareness of US security and compliance standards will be vital for any partnerships, product integrations, or talent exchanges.
As previous newsletters have highlighted, strategic partnerships and a robust governance framework are critical for successful AI adoption at enterprise scale - a message at the very heart of the Genesis Mission.
As the Genesis Mission accelerates, it will demand a blend of technical excellence, compliance rigour, and strategic vision. For enterprises, staying close to these shifts means we can spot new opportunities, adapt to emerging standards, and keep ourselves at the leading edge of AI-enabled enterprise.

POB’s closing thoughts
I’ve spoken before about how impressed I am by the voice capabilities (and the pace of development) from ElevenLabs, and I noticed this week that they published details of a partnership with food delivery firm Deliveroo to enhance rider and restaurant experience.
The company is using ElevenLabs’ AI voice agents to automate some very specific but high‑value operational jobs: re‑engaging inactive rider applicants, calling restaurants to verify whether they are genuinely open, and nudging partners to activate Rider Check‑In tags after installation. Early numbers are strong, with around 80 per cent of rider applicants re‑engaged, a 75 per cent restaurant contact rate for opening‑hours checks, and 86 per cent of partner sites successfully contacted about tag activation, which in turn reduces manual chasing for local operations teams and improves the quality of Deliveroo’s live operational data.
For us, this is a neat pattern to borrow: start with phone‑ or email‑heavy journeys that are repetitive, multilingual and outcomes‑driven, then let voice agents handle the volume while humans focus on edge cases and relationship‑building. The Deliveroo pilots sit in the same family as other agentic AI examples covered in recent issues, where the value comes from embedding agents into concrete workflows with clear guardrails and success metrics, rather than launching yet another generic assistant and hoping for the best.
I’m going to finish this week with a few AI related Black Friday bargains (Happy belated Thanksgiving to our American readers!), on some of my favourite hardware.
The Soundcore Work by Anker AI recorder is £30 off and now £119 at Amazon
The FoCase Note AI Voice Recorder (which I use) is down to £35 at Amazon
Gen 1 Meta Ray-Bans are 20% off at Vision Express
The Pixel Pro 10 is £100 off at Google, has special trade in deals AND includes a free year of Google AI Pro!
The Rabbit R1, which I actually wouldn’t recommend to anyone, is 20% off on their website
Thanks for reading, I hope you have a great weekend! 👍
I’d love to hear your feedback on whether you enjoy reading the Substack, find it useful, or if you would like to see something different in a future post. What AI topics are you most interested in for future explainers? Are there any specific AI tools or developments you'd like to see covered? Remember, if you have any questions around this Substack, AI or how Davies can help your business, you can reply to this message to reach me directly.
Finally, remember that while I may mention interesting new services in this post, you shouldn’t upload or enter business data into any external web service or application without ensuring it has been explicitly approved for use.
Disclaimer: The views and opinions expressed in this post are my own and do not necessarily reflect those of my employer.