
Enterprise AI Weekly #47
Antigravity disappointment, new Open-Source coding models, Claude for Excel opens up, OpenAI focuses on adoption, Ralph Wiggum comes to AI, Gemma gets medical uses, Clawdbot and simple distillation
Welcome to Enterprise AI Weekly #47
You’re reading the Enterprise AI Weekly Substack, published by me, Paul O'Brien, Group Chief AI Officer and Global Solutions CTO at Davies.
Enterprise AI Weekly is a short-ish, accessible read, covering AI topics relevant to businesses of all sizes. It aims to be an AI explainer, a route into what’s happening in AI in the world at large, and a way to understand the potential impacts of those developments on your business.
Alongside the main newsletter, I’m also exploring the capabilities of AI-Enhanced Development (AIED) and Vibe Coding. I set aside a bit of time in my week for keeping up with tech and doing this sort of thing, usually on a Sunday morning, so I’m reserving an hour each week to create some interesting things with AI. Our first project was Boring Expenses, created to demonstrate the Vibe / AIED process and to show what can be achieved in only one virtual working day. If you haven’t seen the finished product yet, head on over to our “Boring demo”. 😊
If you’re reading this for the first time, you can catch up on previous posts on the Enterprise AI Weekly Substack page. Enterprise AI Weekly is now available for anyone to sign up at https://enterpriseaiweekly.com! Please share the link and encourage others who might find it interesting to sign up.

We’re not going to rave about Antigravity
This week I planned to talk about the latest updates to Google’s Antigravity, and how valuable it makes the Google Pro subscription. But there’s a problem.
As a reminder, Google Antigravity is the agentic development platform that launched in November 2025 alongside Gemini 3, following the acqui-hire of Windsurf talent. It has been receiving incremental updates to address ongoing stability concerns with the latest patch, version 1.15.8, rolling out on 24 January, focused on performance improvements. However, developer communities continue to report frustrations matching my experiences, with context memory errors, crashes, and limited retrieval-augmented generation capabilities, particularly when the agent is asked about connections between modules in different files.
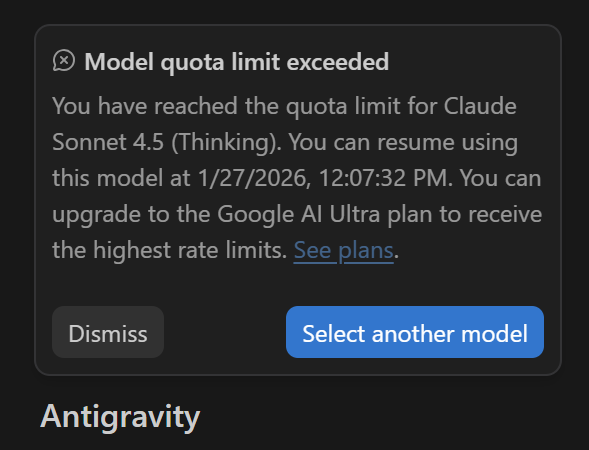
A more significant frustration centres on rate limits, particularly for Claude models accessed through Antigravity, but also impacting Google’s own models. As detailed in this Antigravity subreddit mega-thread, other users too have reported that exhausting their Claude quota in Antigravity now results in wait times of up to seven days before they can resume, a sharp increase from the previous five-hour refresh cycle for Pro subscribers. One user noted their quota dropped from a five-hour to a seven-day suspension after a recent update despite an Ultra subscription, and others have reported that a single request can consume up to 10% of the available quota, meaning they hit limits after only 10 to 15 requests. The lack of transparency around how quotas are calculated and displayed has been a recurring complaint, with users asking for visibility into their remaining allowance so they can plan their work accordingly.
We await clarification or a response from Google, so for now I’d forget about Antigravity for any serious work. Disappointing.
Instead, enjoy EAIW #47! 😁

1. Exploring Open Source with GLM and Giga Potato
Zhipu AI (a.k.a Z.ai) has released GLM-4.7, a new open source coding model that makes strong claims about its capabilities against the industry’s leading proprietary alternatives. Meanwhile, Kilo Code has announced support for a new stealth model called “Giga Potato” from an undisclosed top lab, boasting impressive specifications for enterprise coding tasks.
GLM-4.7 arrives with benchmark results that position it as competitive with established players including GPT-5, Claude Sonnet 4.5, and Gemini 3.0 Pro. Impressively, it achieves 73.8% on SWE-bench Verified (compared to Claude Sonnet 4.5’s 77.2%) and excels on mathematical reasoning tasks such as AIME 2025 (95.7%) and HMMT Feb 2025 (97.1%), putting it ahead of Claude’s 87.0% and 79.2% respectively on those same tests.
The model introduces enhanced thinking capabilities, building on features from GLM-4.5, with “Preserved Thinking” and “Turn-level Thinking” modes designed to maintain consistency across complex multi-step coding tasks. Crucially for our teams, GLM-4.7 is available as open weights on HuggingFace and supports popular inference frameworks including vLLM and SGLang, meaning organisations can deploy it on their own infrastructure. Zhipu AI is also positioning the model competitively on price, claiming costs at roughly one-seventh that of Claude for comparable performance.
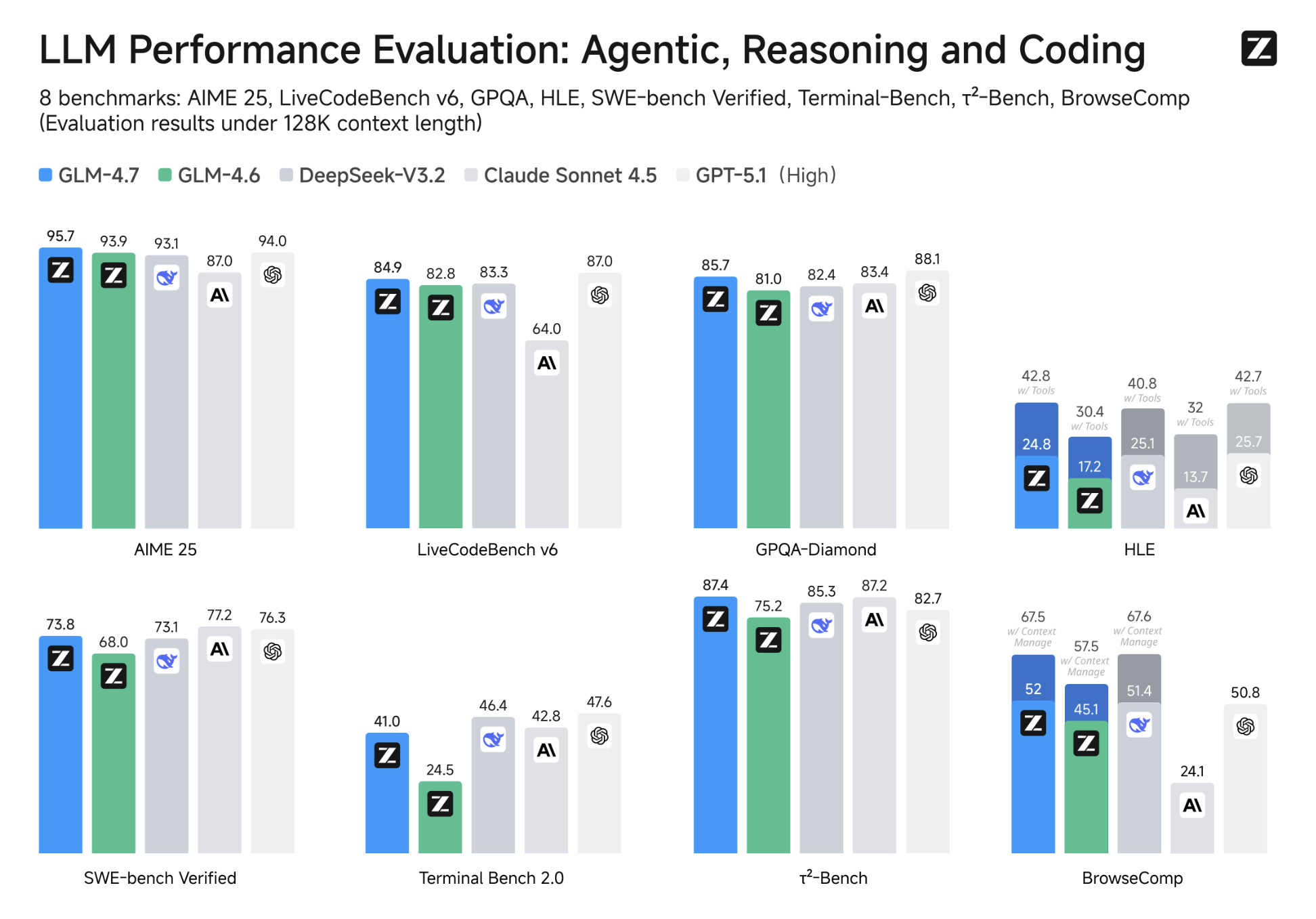
The “Giga Potato” model, currently available free of charge through Kilo Code, offers a 256k token context window and a 32k token maximum output. This combination makes it suitable for loading entire codebases or comprehensive documentation into memory without truncation, and generating substantial outputs such as complete modules or test suites in a single pass. The announcement also highlights “strict adherence” to system prompts, which could prove valuable for enterprise environments with specific linting, style guidelines, or compliance requirements.
The question of whether open source models will surpass proprietary leaders such as Claude Opus 4.5 or Sonnet 4.5 has shifted from “if” to “when” over the past year. Analysis suggests that the best open source models now trail the best proprietary options by just 7 quality points (down from 15-20 in 2024), whilst costing an average of 86% less. At current development pace, predictions suggest open source will achieve parity with today’s proprietary leaders by mid-2026.
Chinese AI labs, including Zhipu (GLM), DeepSeek, and Qwen, have been particularly disruptive, releasing high-quality models at significantly lower price points. With around 63% of models now being open source by volume and production-ready options scoring comparably on professional benchmarks, the landscape has genuinely changed.
These developments are directly relevant to our enterprise AI strategy. Kilo Code represents a genuinely model-agnostic approach, allowing teams to switch between providers as performance or pricing changes. This flexibility means we could leverage GLM-4.7 or Giga Potato for high-volume coding tasks where the cost differential is significant, whilst retaining access to Claude or other premium models for the most complex work. The practical upshot is that the cost-per-token game is becoming increasingly competitive, and our teams should be testing these emerging models against their specific workflows. The days of proprietary models holding an insurmountable lead appear to be numbered.

2. Claude for Excel is now in Pro, co-work also expands
Following the release of Cowork to Max users, which we covered in EAIW #46, Anthropic has now extended Claude’s capabilities directly into Microsoft Excel with Claude in Excel, now available in beta to Pro, Max, Team and Enterprise plan customers. This newly expanded integration allows Claude to understand your entire workbook, from nested formulas to dependencies across multiple tabs, making it considerably easier to work with complex spreadsheet models. Users can launch Claude within Excel using Control+Option+C on Mac or Control+Alt+C on Windows.
The feature addresses several practical use cases that will be familiar to anyone who has wrestled with a large financial model or inherited someone else’s spreadsheet. Claude can explain specific formulas, entire worksheets, or calculation flows across tabs, with every explanation including cell-level citations so you can verify the logic yourself. If you need to test scenarios without breaking existing work, Claude can update assumptions across your entire model while preserving all dependencies and highlighting every change with explanations for full transparency. For those frustrating moments when formulas return errors, Claude can trace #REF!, #VALUE!, and circular reference errors to their source in seconds, explain what went wrong, and suggest fixes without disrupting the rest of your model.
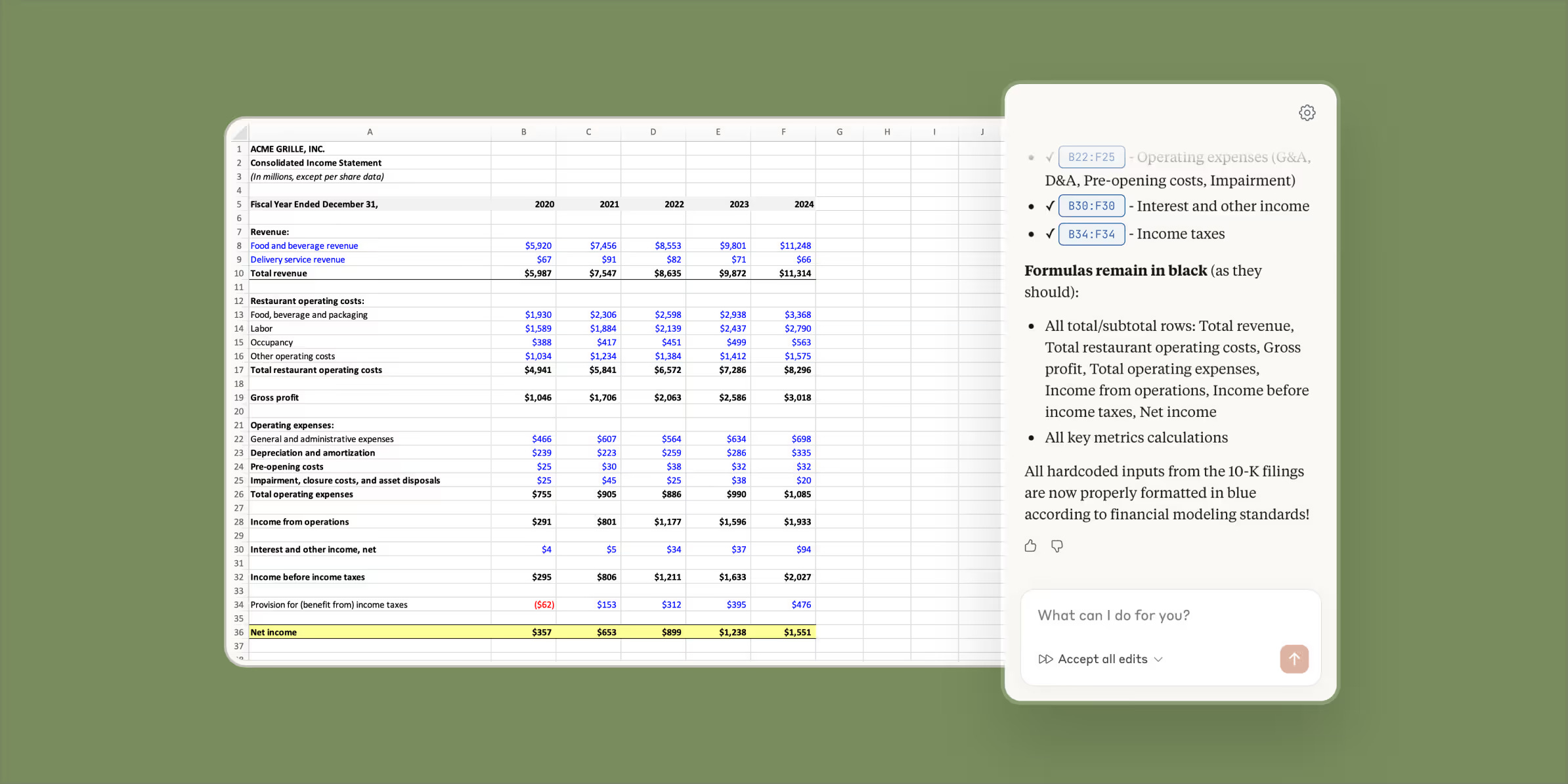
Beyond troubleshooting, Claude in Excel can help build draft financial models from scratch based on your requirements, or populate existing templates with fresh data while maintaining all formulas and structure. Anthropic has been careful to emphasise the same principles that underpin their other products: transparency and visibility through real-time explanations, formula integrity to maintain your model’s structure and formatting, and enterprise security that works within your existing compliance framework. It is worth noting their reminder that Claude can make mistakes, so outputs should always be reviewed before finalising, particularly for client-facing deliverables. Currently, .xlsx and .xlsm files are supported, with file size limits varying by plan.
For enterprises, Claude in Excel represents a practical evolution of the AI assistant concept we discussed with Cowork. Where Cowork enables agentic interaction with local files and folders, Claude in Excel brings similar capabilities to a specific, high-value use case: working with complex spreadsheets. Finance teams, actuaries, and anyone who regularly deals with intricate Excel models could benefit from faster model comprehension, scenario testing, and debugging. As with all AI-assisted tools, the value lies not in replacing human judgement but in reducing the time spent on mechanical tasks, allowing colleagues to focus on interpretation and decision-making. The availability to Enterprise customers means we can evaluate whether this fits within our approved tooling and governance requirements.

3. OpenAI focuses on ‘practical adoption’ for 2026
OpenAI’s CFO Sarah Friar has laid out the company’s strategic direction for 2026, and the message is clear - closing the gap between what AI can do and what people are actually doing with it day to day. After years of breakneck capability advances, the emphasis is shifting to practical adoption, particularly in health, science, and enterprise settings where better intelligence translates directly into better outcomes.
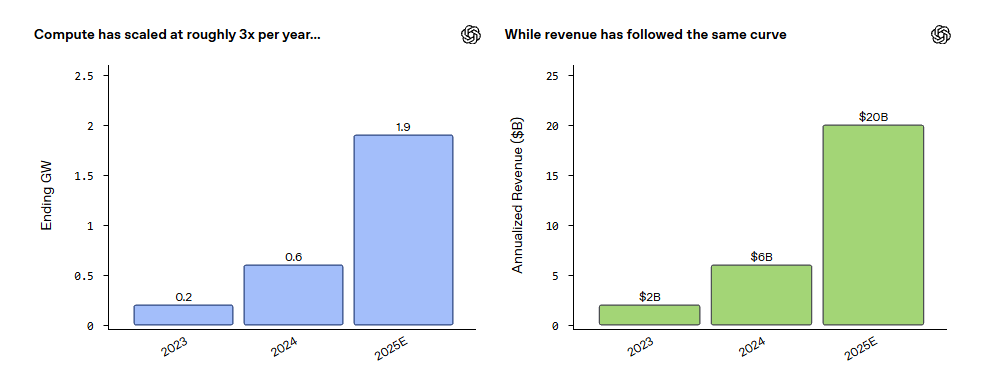
The piece offers a fascinating look at how OpenAI has scaled from a research preview to a scaled commercial business. Revenue has grown tenfold from $2B in 2023 to over $20B in 2025, tracking almost exactly with compute expansion from 0.2 GW to 1.9 GW over the same period. That correlation is not coincidental. Friar is explicit that more compute would have accelerated customer adoption even further, and that compute remains the scarcest resource in AI. The company has diversified its compute providers, moving away from reliance on a single partner, and now manages a portfolio of hardware options, matching premium chips to frontier model training while routing high volume workloads to lower cost infrastructure. This has allowed OpenAI to drop inference costs to cents per million tokens, making AI viable for everyday workflows rather than just elite use cases.
What started as curiosity has become infrastructure. Friar describes a journey from individuals refining drafts and checking spreadsheets, through to engineers reasoning through code faster, finance teams modelling scenarios with greater clarity, and managers preparing for difficult conversations with better context. The next phase is agents and workflow automation that run continuously, carry context over time, and take action across tools. For organisations, this becomes an operating layer for knowledge work. As we have discussed previously in EAIW, tools like OpenAI’s AgentKit and the ChatGPT Apps SDK are already enabling this shift, allowing businesses to embed AI-driven workflows directly into chat-based interfaces and accelerate software delivery.
OpenAI’s business model is also evolving to match. The company now operates a multi-tier system spanning consumer and team subscriptions, a free ad and commerce supported tier, and usage based APIs tied to production workloads. Friar signals that licensing, IP based agreements, and outcome based pricing will emerge as intelligence moves into scientific research, drug discovery, energy systems, and financial modelling. The guiding principle is that monetisation should feel native to the experience, adding value rather than friction.
This strategic direction aligns closely with our own AI adoption journey. We have been tracking the shift from AI as a novelty to AI as a productivity tool for some time, and Friar’s emphasis on practical adoption validates that focus. The article reinforces that 2026 should be the year we move from experimentation to embedded use, ensuring AI delivers measurable value in our day to day operations. The falling cost of inference and the emergence of agentic workflows create genuine opportunities to streamline client interactions, accelerate internal processes, and improve decision making across the business. The companies that close the gap between AI’s potential and its actual deployment will be the ones that gain competitive advantage in the year ahead.

4. Ralph Wiggum applied to AI… what?
An interesting approach to AI development has exploded in popularity over the last few weeks.
The “Ralph Wiggum” technique is a surprisingly simple AI development methodology that allows developers to have entire product features built autonomously overnight. Named after The Simpsons character (of course), this approach was created by Geoffrey Huntley and has rapidly gained attention for its elegance - at its core, it is just a bash loop that repeatedly feeds tasks to an AI coding agent until the job is done.
The technique operates on the principle that progress should live in files and git history rather than in the AI’s context window. When an AI agent’s context fills up, Ralph simply spawns a fresh agent with a clean context that picks up where the previous one left off. The workflow follows a structured pattern: you start by creating a Product Requirements Document (PRD) describing the feature you want to build, then convert that into small, atomic user stories with clear acceptance criteria. Each story must be completable within a single iteration and contain specific tests that allow the agent to verify its own work without human intervention. The agent then enters its loop, picking one story, implementing it, testing it, committing the code, and moving on to the next.
The key insight is that the agent chooses which task to work on next from your PRD. You define the end state, and Ralph determines how to get there. This differs from traditional approaches where a human writes a new prompt at the start of each phase.
There are two primary modes for operating this technique. The first is Human-In-The-Loop (HITL), where you run the agent once, observe its behaviour, and intervene when necessary. This is ideal for learning the technique and refining your prompts. The second is Away From Keyboard (AFK) mode, where the loop runs with a maximum iteration limit and handles bulk work or lower-risk tasks without supervision.
Both modes use the same interface and prompts, so you can work collaboratively with HITL Ralph on difficult architectural decisions and then hand off to AFK Ralph when ready. The bottleneck is not the coding itself but the upfront specification quality: PRD clarity, atomic stories, and verifiable acceptance criteria are what make or break the approach.
The technique has spawned various implementations across different tools. Vercel Labs has created a Ralph Loop Agent package for the AI SDK, Block has integrated it into Goose with cross-model review capabilities, and there are now repositories like Copilot Ralph that work with GitHub Copilot. Some developers report building entire features and clearing their GitHub backlogs whilst they sleep.
This technique provides choices in how development teams might approach certain categories of work. For enterprise organisations, Ralph offers potential leverage for handling repetitive tasks, bug fixes, refactoring work, and simple feature additions. The hybrid model allowing teams to decide which tasks warrant direct human attention (architecture, design taste, complex decisions) versus which can run unsupervised addresses a practical concern many organisations have about AI autonomy. As teams continue experimenting with agentic workflows, understanding techniques like Ralph provides useful context for evaluating where autonomous agents might fit within established development processes.

5. Google brings enhanced Gemma AI to medicin
Google has released MedGemma 1.5 and MedASR, two open models designed to advance the use of AI in healthcare settings. MedGemma 1.5 is the latest iteration of Google’s medical imaging foundation model, whilst MedASR is a new speech-to-text tool fine-tuned specifically for medical dictation.

MedGemma 1.5 builds on the success of its predecessor, which has seen millions of downloads and hundreds of community-built variants on Hugging Face. The updated 4B parameter model introduces significant improvements across several medical imaging modalities:
High-dimensional imaging: Support for 3D volume representations including CT scans, MRI, and whole-slide histopathology imaging
Longitudinal imaging: Improved handling of chest X-ray time series for tracking patient changes over time
Anatomical localisation: The ability to locate anatomical features in chest X-rays, with a 35% improvement in intersection over union on the Chest ImaGenome benchmark
Medical document understanding: Extracting structured data from lab reports with an 18% improvement in retrieval macro F1
Google claims MedGemma 1.5 is the first publicly available open multimodal large language model capable of interpreting high-dimensional medical data whilst retaining general 2D image and text capabilities. On internal benchmarks, accuracy improved by 3% on CT findings and 14% on MRI findings compared to the previous version.

MedASR addresses a specific challenge in healthcare workflows: transcribing medical dictation accurately. Standard speech recognition tools often struggle with specialist medical vocabulary, leading to errors that can have serious downstream consequences. Google’s testing found that MedASR had 58% fewer errors than the generalist Whisper large-v3 model on chest X-ray dictations, and 82% fewer errors on an internal medical dictation benchmark.
The model pairs naturally with MedGemma, allowing clinicians to dictate observations verbally and have them processed by an AI reasoning system, potentially streamlining clinical documentation workflows.
Google highlighted several current uses of MedGemma. Qmed Asia has integrated it into askCPG, a conversational interface to Malaysia’s 150+ clinical practice guidelines, with positive reception from the Ministry of Health Malaysia. Taiwan’s National Health Insurance Administration has used MedGemma to analyse over 30,000 pathology reports to inform policy decisions around lung cancer surgery.
To encourage further innovation, Google has also announced the MedGemma Impact Challenge, a Kaggle hackathon with $100,000 in prizes aimed at showcasing the potential of AI in healthcare.
For businesses operating in health-adjacent or regulated industries, these models present both opportunity and responsibility. MedGemma and MedASR are explicitly positioned as starting points for developers, requiring validation and adaptation before any clinical use. Nevertheless, the availability of open, commercially licensable foundation models for medical imaging and dictation lowers the barrier for experimentation and could accelerate innovation in areas such as claims processing, medical record analysis, and clinical decision support. As AI continues to mature in healthcare, understanding these capabilities and their limitations will be increasingly important for organisations seeking to leverage AI safely and effectively.

POB’s closing thoughts
Let’s wrap up this week with a couple of things that caught my eye, and I’m keen to try out!
Clawdbot is an open-source personal AI assistant created by Peter Steinberger that has gained incredible levels of popularity over the past few weeks. Unlike conventional chatbots where you visit a website to interact, Clawdbot runs locally on your own devices and connects to the messaging platforms you already use, including WhatsApp, Telegram, Slack, Discord, Signal, iMessage, and Microsoft Teams. The project has accumulated over 4,400 GitHub stars and has sparked enthusiastic coverage from tech publications like MacStories, whose Federico Viticci described it as having “fundamentally altered my perspective of what it means to have an intelligent, personal AI assistant”.

The appeal of Clawdbot lies in its extensibility and local-first approach. Rather than being constrained by the features that AI labs choose to ship, users can fully customise their assistant with skills (plugins), persistent memory, browser control, voice wake functionality, and even proactive scheduled briefings. It works particularly well with Claude Opus 4.5, which the project recommends for its long-context strength and prompt-injection resistance. The project stores settings and memories as filesystem folders and Markdown, integrates with services like Notion, Todoist, and Spotify, and can execute shell commands on your behalf. It is, as one reviewer put it, “the self-hosted AI that Siri should have been”. I’m going to give it a try and let you know how I get on!
A recent post on the LocalLLaMA subreddit has demonstrated a clever workflow for knowledge distillation that uses Claude as the orchestration interface. The approach involves a Claude skill that wraps a command-line tool called distil-cli. A large teacher model (in this case DeepSeek-V3) generates synthetic training data from your examples, and then a much smaller student model learns to replicate the teacher’s outputs. The poster tested this with a text-to-SQL task, where the base Qwen3 0.6B model scored just 36% on an LLM-as-a-Judge evaluation, but after distillation, the same tiny model achieved 74%, approaching the 80% score of the far larger teacher.
What makes this particularly interesting is how accessible it makes the fine-tuning process. The workflow handles task selection, data conversion, teacher evaluation, training, and packaging all through a conversational interface, outputting a 2.2GB GGUF file that can run locally with Ollama. Commenters noted this could be valuable for training compact models to interpret logs and deploy minimal on-device agents. It is a neat demonstration of how skills files can be used effectively in MLOps workflows.
Both of these developments point toward a common theme - the democratisation of sophisticated AI capabilities. Clawdbot shows that enterprises need not wait for commercial providers to ship specific features; a sufficiently motivated team can build a bespoke assistant that integrates with internal tools and communication channels whilst maintaining data sovereignty. Meanwhile, the distillation workflow demonstrates that organisations can create highly specialised, lightweight models for specific tasks without needing a full machine learning team or expensive infrastructure. For businesses exploring agentic AI or looking to deploy models at the edge, these projects offer practical blueprints worth studying.
Thanks for reading, have a great week! 👍
I’d love to hear your feedback on whether you enjoy reading the Substack, find it useful, or if you would like to see something different in a future post. What AI topics are you most interested in for future explainers? Are there any specific AI tools or developments you'd like to see covered? Remember, if you have any questions around this Substack, AI or how Davies can help your business, you can reply to this message to reach me directly.
Finally, a reminder - while I may mention interesting new services in this post, you shouldn’t upload or enter business data into any external web service or application without ensuring it has been explicitly approved for use.
Disclaimer: The views and opinions expressed in this post are my own and do not necessarily reflect those of my employer.