
Enterprise AI Weekly #48
Clawdbot is now OpenClaw, lots of open source models arrive, MCP apps come to Claude, OpenAI releases 'Prism' for research, Sub-agents take off, PaddleOCR VL gets upgraded, backup your stuff!

Welcome to Enterprise AI Weekly #48
You’re reading the Enterprise AI Weekly Substack, published by me, Paul O'Brien, Group Chief AI Officer and Global Solutions CTO at Davies.
Enterprise AI Weekly is a short-ish, accessible read, covering AI topics relevant to businesses of all sizes. It aims to be an AI explainer, a route into what’s happening in AI in the world at large, and a way to understand the potential impacts of those developments on your business.
Alongside the main newsletter, I’m also exploring the capabilities of AI-Enhanced Development (AIED) and Vibe Coding. I set aside a bit of time in my week for keeping up with tech and doing this sort of thing, usually on a Sunday morning, so I’m reserving an hour each week to create some interesting things with AI. Our first project was Boring Expenses, created to demonstrate the Vibe / AIED process and to show what can be achieved in only one virtual working day. If you haven’t seen the finished product yet, head on over to our “Boring demo”. 😊
If you’re reading this for the first time, you can catch up on previous posts on the Enterprise AI Weekly Substack page. Enterprise AI Weekly is now available for anyone to sign up at https://enterpriseaiweekly.com! Please share the link and encourage others who might find it interesting to sign up.

Clawdbot → Moltbot → OpenClaw…?
Clawdbot’s identity crisis has now completed its trilogy, with the project sprinting from Clawdbot to Moltbot and, as of the latest rebrand, to OpenClaw in the space of days. The original rename was nudged along by Anthropic’s polite but pointed trademark concerns around “Clawdbot”, leading to the slightly niche “Moltbot” branding before the team settled on OpenClaw as the more durable, open‑source‑friendly badge. Far from slowing it down, the name chaos has poured fuel on the hype - OpenClaw and its lobster mascot are everywhere on X, Reddit and Discord, with maintainers, influencers and researchers all weighing in on what looks like the first truly mainstream “personal agent that actually does things”. The ecosystem has even started to metastasise into spin‑offs like Moltbook, a kind of social network where people’s OpenClaw instances chat to each other, which is exactly as sci‑fi and slightly alarming as it sounds.
Underneath the memes and lobster jokes, though, the security story is getting louder and more serious every day. OpenClaw instances can run shell commands, read and write local files and call arbitrary “skills”, which is great for power users but a gift for anyone looking to exfiltrate data or plant malware if a config is even slightly off. Researchers scanning the internet are already finding exposed deployments leaking plaintext API keys, OAuth tokens and chat histories, and documenting malicious skills on ClawHub that convince users to paste opaque terminal commands which happily fetch remote scripts. Cisco’s security team and others have demonstrated prompt‑injection‑powered data exfiltration, while even the OpenClaw maintainers are now publicly warning that if you cannot confidently live at the command line, this project is “far too dangerous” for you right now.
We'll be doing an OpenClaw deep-dive in a future edition, digging into what this all means for enterprises, shadow IT and our own approach to agent security

1. A raft of powerful Open Source models arrive
Open source model releases are now arriving so quickly that “this week’s models” increasingly look like a mini product line rather than a couple of curiosities, and this week has been particularly busy on that front.
Arcee AI’s Trinity Large is a 400‑billion parameter open‑weight model that very deliberately takes aim at Meta’s Llama line and the broader closed frontier tier. The interesting bit for enterprises is not just size, but the packaging: Arcee is shipping three distinct variants under a permanent Apache 2.0 licence, which is about as friendly as it gets for corporate use.
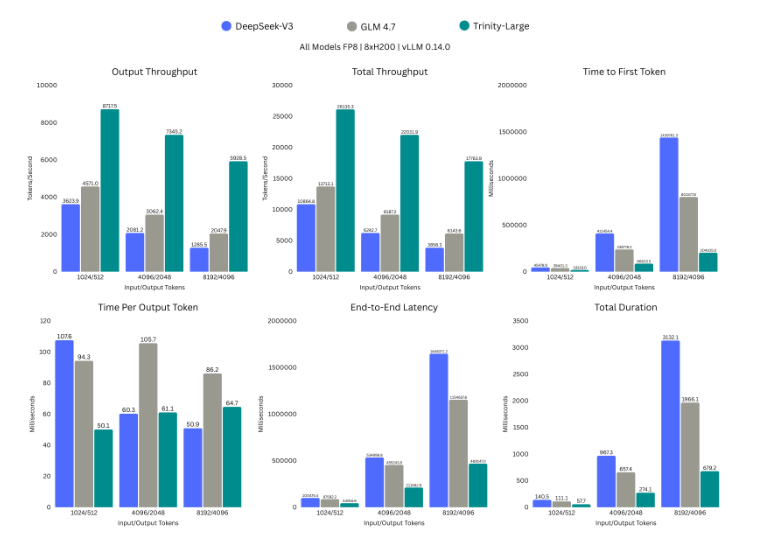
The variants are: a Trinity Large Preview model for general chat and instruction following, a Trinity Large Base model without post‑training for research, and a “TrueBase” version that is scrubbed of instruction and alignment data so you can apply your own fine‑tuning from a clean starting point. That last option is particularly useful if you care about a model that reflects your organisation’s policies rather than someone else’s, or if your lawyers twitch at the idea of reversing pre‑existing alignment choices.
The announcement blog post makes for interesting reading on their approach and results to date, I’d highly recommend checking it out.
Taking it up a level, Moonshot’s Kimi K2.5 lands as a 1‑trillion parameter Mixture‑of‑Experts model (with roughly 32B parameters active per token) and is being positioned as “the most powerful open‑source multimodal model” available. It is natively multimodal rather than a text model with vision bolted on, having been further pretrained on around 15T mixed visual and text tokens, which shows up in stronger code‑plus‑UI and document workflows.
Two aspects will interest enterprise teams. First, K2.5 is licensed permissively, giving broad freedom to self‑host and embed in products. Second, K2.5 introduces an “agent swarm” approach where the model can coordinate large numbers of sub‑agents and tools in parallel, reporting up to 4.5× speed improvements for complex tasks that involve many external calls. Practically, that points to more efficient orchestration for things like multi‑system reconciliations or large‑scale code refactors, assuming you design the surrounding guardrails sensibly.
It doesn’t stop there! Alibaba’s Qwen 3 Max Thinking is not an open‑weights checkpoint you download, but it is part of a family where many variants are released under Apache‑style licences, and Max Thinking is already exposed through several infrastructure providers. The defining feature is that it cleanly separates a “thinking mode” which integrates deliberate reasoning with built‑in web search, web extraction and code interpreter tools, from a faster non‑thinking mode.
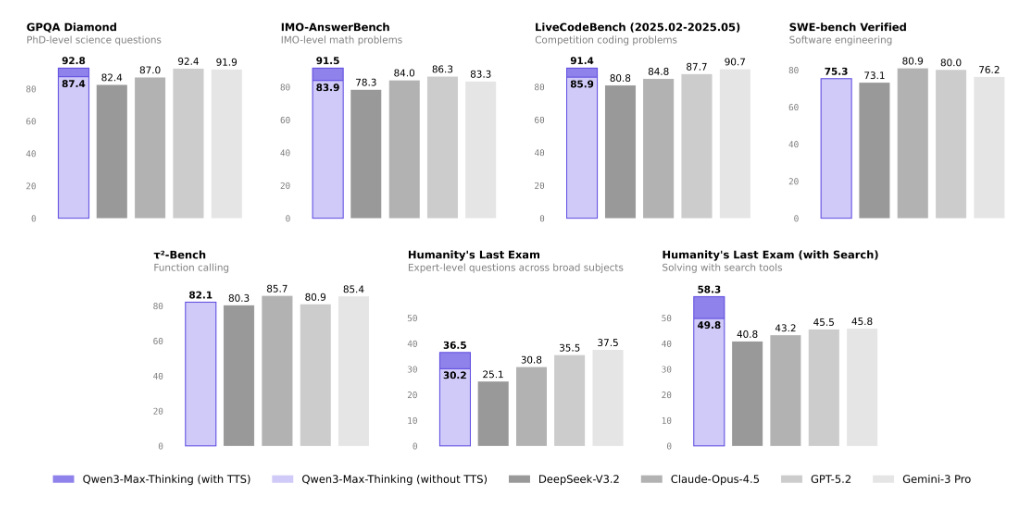
For enterprises, that split maps neatly to different workloads: rapid chat and UI‑level tasks versus slower, audited reasoning for risk, compliance or deep analysis. Qwen 3 brings significantly improved reasoning benchmarks over the Qwen2.5 line, better human preference alignment, and support for 256k‑token contexts extendable towards the million‑token mark, which is in the territory of whole repositories or very large policy bundles. In practical terms, that makes it a serious candidate for long‑document review, codebase understanding and agentic workflows where you want the model to call tools but still take its time to think.
Stepping back from the named trio, the wider landscape has moved again. Rankings of open‑weight models for January already place Kimi K2.5 at or near the top of open source quality tables, ahead of previous leaders such as DeepSeek V3.2 and Qwen3‑235B, and argue that for many coding workloads open models now match or surpass proprietary options. In parallel, a series of local‑first tools highlight OpenAI’s GPT‑OSS and other open‑weight options, reinforcing the sense that “good enough” models for on‑premise use are now plentiful rather than rare.
Looking slightly ahead, DeepSeek V4 is shaping up as the next big open release to watch. Multiple independent write‑ups converge on a mid‑February 2026 window, deliberately timed around Lunar New Year, and expect V4 to continue DeepSeek’s pattern of open‑weight models optimised for long‑context coding and engineering tasks rather than synthetic benchmarks. The anticipated focus is on stable multi‑step reasoning, better long‑context quality for large codebases and documents, and much more efficient inference, which together could make V4 one of the default choices for local coding assistants and CI‑integrated agents in the first half of this year.
Oh, and rumours are that the next version of Anthropic’s Claude Opus is only days away, and will change the game again. Exciting times!
For enterprises, the pattern here is as important as the individual logos. Trinity Large shows that genuinely frontier‑scale, Apache‑licensed models are no longer a theoretical concept, but something you can plan around for fully self‑hosted, policy‑aligned deployments. Kimi K2.5 demonstrates that the open community can now offer multimodal and agent‑oriented capabilities good enough for real “getting work done” scenarios, not just demos, and that they are willing to do so with licences that sit comfortably inside most corporate risk appetites.
Qwen 3 Max Thinking illustrates where model design is heading: explicit, controllable “slow thinking” modes, long‑context support, and embedded tool use that can be harnessed rather than feared. DeepSeek V4, if it lands as expected, will likely reinforce a world where our choice is not “closed and powerful” versus “open and weak”, but which open model best fits each workload and governance model. For us, that means our AI strategy needs to assume a rolling pipeline of credible open options, and to invest more in platform, evaluation and governance layers so that swapping models in and out becomes a routine engineering decision rather than a two‑year programme.

2. MCP expands with ‘MCP Apps’ in Claude
MCP apps have arrived in Claude! Building on a draft specification from November, MCP Apps turns AI responses from static text into interactive mini‑applications that run directly inside tools like Claude and ChatGPT, using the same open Model Context Protocol that we have been tracking for the past year.
MCP Apps is the first official extension to the Model Context Protocol, adding a UI layer on top of the existing tools, resources and prompts we already know. Instead of a tool returning only text or JSON, an MCP server can now return an “app definition” that the client renders as a live interface inside the conversation, such as dashboards, forms or multi‑step workflows. Under the hood, this is described through a JSON manifest that defines components, state and actions, which the host parses and turns into native‑feeling UI.
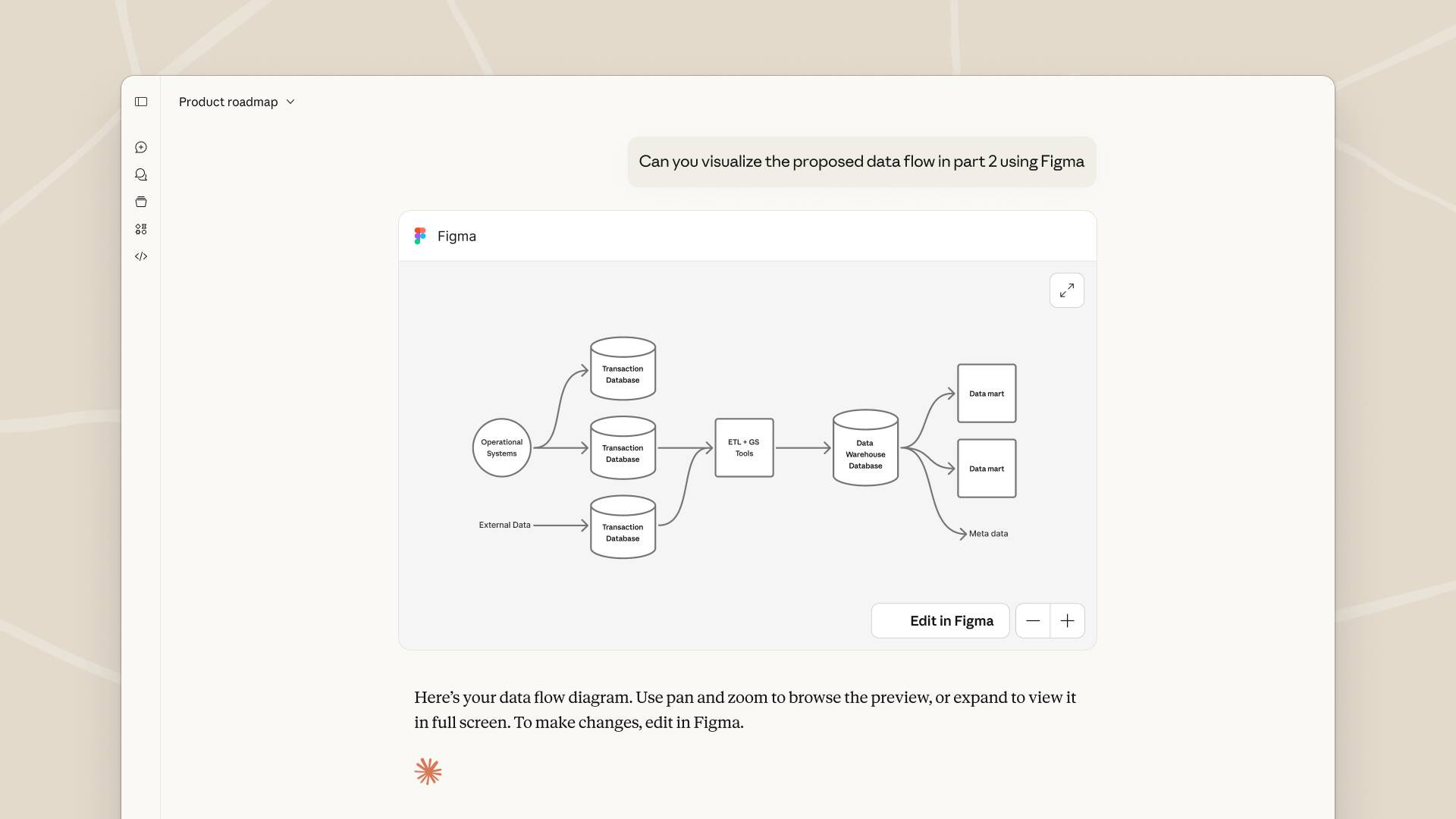
The model can embed these app definitions alongside its normal replies, so a single answer can both explain and give you something you can click, type into, or submit. From the protocol’s perspective, MCP Apps extends rather than replaces the existing architecture - hosts remain MCP clients, servers still expose tools and resources, but they can now declare UI resources (for example an HTML template with a special profile) that are bound to specific tools.
MCP Apps effectively closes the loop between “chat about a task” and “do the task in a proper UI” without forcing the user to jump out to a separate web application. That makes it much easier to build rich, reusable experiences - think claim triage forms, quote builders, data explorers or approval consoles - and surface them contextually when the model thinks they will help.

This also creates a consistent way for different AI hosts to support the same interactive tools, just as we have already seen MCP used to standardise access to services like GitHub and Google Cloud. In practice, an MCP App built once can be reused across multiple environments that speak MCP, rather than every vendor inventing its own plug‑in format. That fits neatly with themes we have discussed previously around MCP acting as “USB‑C for AI” and around chat‑embedded apps such as OpenAI’s earlier Apps SDK.
For enterprises, MCP Apps is attractive because it keeps business logic and data access inside governed MCP servers, while giving users a far better experience than raw tool calls in a chat log. However, there are clear questions for security and risk teams - adopting MCP Apps means allowing third‑party UI code to run inside AI clients, which introduces familiar concerns around supply chain risk, data exfiltration and compliance with internal UI standards.
The extension also raises product and governance questions - who owns the lifecycle of these apps, how do we test and version them, and how do we ensure that sensitive actions still go through appropriate approval flows rather than being buried in a conversational side‑panel. As we have already seen with early MCP deployments, the protocol makes deep automation possible, but it must be paired with strong identity, permissions and monitoring if it is to be accepted by regulators and internal audit.

3. OpenAI introduces their ‘Prism’ research tool
OpenAI Prism is a new, AI‑native workspace for scientific writing that combines a cloud LaTeX editor with GPT‑5.2 as an embedded “co‑author” for maths‑heavy research papers.
Prism is a free, browser‑based environment for drafting, editing and compiling LaTeX documents, with live preview and collaboration built in. It is built on top of Crixet, an existing cloud LaTeX platform that OpenAI acquired, then upgraded with deep model integration rather than reinventing the editor from scratch. Anyone with a ChatGPT account can use it, with no per‑seat limits and support for unlimited projects and collaborators, which is a departure compared with most commercial research tools.
Prism’s core feature is tight integration with GPT‑5.2, OpenAI’s latest model tuned for mathematical and scientific reasoning. Within a paper, researchers can:
Draft and revise prose, equations and sections with full document context, including prior text, structure, figures and citations.
Ask the model to check reasoning, suggest alternative proofs, and explore hypotheses in domains with strong formal underpinnings such as maths and theoretical physics.
Run literature search (for example across arXiv) directly in context of the current manuscript, then integrate and rephrase related work.
Automate LaTeX‑specific pain points like equation formatting, table layout, citation insertion and error checking.
There are early examples of GPT‑5.2 contributing non‑trivial mathematical results, where the model generated the main steps of a new proof and humans focused on checking and polishing it.
A lot of what Prism can do is theoretically possible by copying fragments into a generic model, but the value is in persistent context and workflow.
Project‑aware context: the AI can “see” the entire project - sections, prior drafts, equations, bibliography - rather than just the last prompt.
LaTeX‑native: the model understands LaTeX syntax, so it edits source directly and keeps outputs compilable, which is far less fiddly than round‑tripping via Word or plain text.
Multimodal and natural interaction: Prism can accept images such as handwritten maths or whiteboard sketches, and there is support for voice‑driven editing, which makes it feel more like an ever‑present assistant than a separate chatbot window.
In effect, Prism turns AI from an occasional side‑tool into a continuous partner embedded in the authoring surface itself.
For an enterprise like ours, the relevance goes well beyond academia.Many of our teams produce long, technical documents with formulas, diagrams and dense references (think pricing models, solvency papers, risk reports). Prism shows how an AI‑native editor can cut friction in drafting, cross‑referencing and formatting, which mirrors the opportunity in our own internal tooling. GPT‑5.2’s strength in mathematical and scientific reasoning suggests similar gains for actuarial models, scenario analysis and method papers, provided we keep humans firmly in the loop for checking assumptions. OpenAI explicitly frames Prism as doing for science what AI coding environments did for software engineering, namely moving from generic chat to task‑specific, context‑rich workspaces. This is the same pattern we have been talking about in earlier newsletters with vibe‑coding tools, AI‑assisted development, and agentic workflows in Excel and other line‑of‑business apps.
Practically, Prism is unlikely to be a tool we point at client data any time soon. However, it is a clear signal of where the ecosystem is heading: sector‑specific, AI‑centred workspaces that wrap existing formats (here LaTeX, elsewhere spreadsheets or policy docs) with highly capable models. Our job is to decide where we want to pilot similar patterns inside the organisation, using approved platforms, so that our own specialists get the same kind of “AI co‑author” advantage as the scientific community.

4. Sub-agent approaches continue to gain traction
Sub-agents are quickly becoming the “multi‑tool” of modern AI systems. Instead of relying on one very clever but easily distracted agent, teams are starting to use collections of smaller, specialised agents that can be dispatched to do focused work and report back.
At heart, a sub-agent is a specialised helper agent that runs separately from your main agent, usually with its own context window, instructions and occasionally its own tools or model. The main agent stays in a relatively clean, slim context, and delegates heavy lifting tasks to sub-agents which then return a concise result for the main agent to incorporate.
This pattern solves three very practical issues that everyone bumps into with “single super-agent” designs - context bloat, slow responses, and tangled prompts where one agent is expected to be a researcher, coder, compliance analyst and project manager all at once. By carving the work into explicit roles, you gain better control, observability and often higher quality outputs for complex workflows.
You can see this pattern emerging across the mainstream tooling ecosystem already. GitHub Copilot Chat introduced “sub-agents” that run as an isolated Copilot session inside your existing chat, suitable for things like deep code analysis, refactoring plans or reviewing large log files, then handing a short summary back to the main chat. Users are leaning on this to keep their main Copilot conversation focused on implementation, while sub-agents do context-heavy work such as research, standards-based code reviews and log analysis.
OpenAI’s Agents SDK bakes the same idea in under the label of “multi-agent systems”, using an orchestrator-subagent pattern (“agents as tools”) and agent handoffs, so one agent can either call another as a tool or explicitly pass control for part of a workflow. Enterprise platforms are following suit: Databricks’ Mosaic AI framework describes multi-agent “supervisor” architectures, where a central supervisor routes tasks to specialist agents for different domains, and Aisera talks about orchestrating domain-specific agents across service and IT operations to improve accuracy, latency and cost control.
Some examples of sub-agent style use cases:
Developer tooling: Copilot sub-agents for refactor suggestions, code audits against house standards, and large-log analysis without polluting the main conversation.
Customer service: OpenAI’s multi-agent demo routes different parts of a customer query to different agents (billing, technical support, policy), coordinated by an orchestrator agent using agent handoffs.
Analytics and knowledge work: Multi-agent supervisor setups on platforms like Databricks, where one agent handles retrieval across data lakes, another focuses on analytics, and a third manages governance or quality checks before results are exposed in tools like Microsoft Teams.
Three drivers are pushing this pattern into the mainstream. First, context windows and tool calls are still finite and billable; offloading heavy analysis to narrow, cheaper or faster agents and returning only a summary is an easy optimisation win. Second, as organisations wire agents into real systems, they need guardrails - having separate “research”, “execution” and “approval” agents that check each other’s work makes audits and risk management more tractable. Third, frameworks have caught up - instead of hand-rolling message-passing, you now get orchestrator/subagent primitives in SDKs and platforms, which reduces the friction of experimenting with multi-agent designs.
For enterprises, the sub‑agent pattern lines up neatly with how our organisations already operates - distinct teams with clear mandates, coordinated through a set of shared processes. In practical terms, sub‑agents give us a way to design AI systems that mirror real operating models - a “front‑door” assistant facing colleagues or customers, with specialist compliance, data‑retrieval, pricing or engineering sub‑agents working in the background. It also gives us a clearer path to incremental adoption: we can start by carving out a scoped sub‑agent for, say, policy interpretation or knowledge retrieval, prove value and safety there, and only then wire it into our broader estate through an orchestrating layer.
As we think about our internal agent strategy this year, it is worth assuming that we will not be managing “one big copilot”, but a fleet of sub‑agents that need governance, routing, observability and lifecycle management, much like microservices did for software a decade ago. That has implications for architecture (how we expose tools and data securely), for operating models (who owns which agents, and how they’re versioned), and for skills (prompt engineering evolving into agent and workflow design). The upside is that this pattern should let us scale AI assistance out across the business while keeping control of cost, quality and risk, which is exactly where our focus needs to be.

5. PaddleOCR gets a powerful upgrade
PaddleOCR-VL-1.5 is a new open-source vision-language model focused on turning messy, real‑world documents into clean, structured data at scale, while staying small enough to deploy in production environments.
PaddleOCR‑VL‑1.5 is an upgraded 0.9B‑parameter vision-language model that combines document understanding, OCR and layout analysis in a single system. It reaches 94.5% accuracy on the OmniDocBench v1.5 benchmark, a state‑of‑the‑art result against both general multimodal models and specialist document parsers.
The model sits in the PaddleOCR ecosystem and is available as open weights on Hugging Face, with integrations into the standard Transformers stack for inference over images and PDFs. Despite the compact size, it is explicitly designed as a production workhorse rather than a research toy, with attention to throughput, GPU efficiency and batch processing of full document sets.
PaddleOCR‑VL‑1.5 is less about “slightly better OCR” and more about treating documents as complex layouts in hostile real‑world conditions.
Notable capabilities include:
Real‑world robustness: The team introduce a “Real5‑OmniDocBench” benchmark that covers five nasty but realistic scenarios - scanning artefacts, skew, page warping, screen photography and awkward illumination. PaddleOCR‑VL‑1.5 delivers top performance across these, including support for irregular, polygon‑shaped layout detection rather than just rectangular boxes.
Text spotting and seal recognition: Beyond pure text detection, the model now supports text spotting (joint text‑line localisation and recognition) plus explicit stamp / seal recognition, and reports new state‑of‑the‑art scores on those tasks. For many regulated workflows, seals and stamps are effectively “business logic encoded in ink”, so this is more important than it first sounds.
Richer document structures: The model recognises formulas, tables, charts and other complex elements in a single pass, with measurable gains on tables and formula parsing versus the previous version. There is also support for automatic cross‑page table merging and heading recognition, which reduces the common problem of long documents being split into unusable fragments.
Multi‑lingual and niche scripts: Language coverage is expanded to 111 languages, with explicit mention of Tibetan and Bengali and improved handling of rare characters, ancient texts, multilingual tables, underlines and checkboxes. That makes it relevant beyond the “OCR a scanned invoice” use case into more awkward archival and international material.
Under the hood, PaddleOCR‑VL‑1.5 builds on an irregular‑layout algorithm, PP‑DocLayoutV3, to do high‑precision layout analysis on skewed and warped pages before feeding text to the language component. The 0.9B‑parameter size is unchanged from the original PaddleOCR‑VL, but the task coverage and benchmark performance are noticeably higher.
If we zoom out from the Hugging Face page, PaddleOCR‑VL‑1.5 fits cleanly into a pattern we have discussed before in Enterprise AI Weekly - specialist models quietly pushing key workflows from “messy and manual” to “machine‑first, human‑checked”. In earlier issues we covered Dots OCR, another open‑source OCR / document parser that impressed with accuracy on handwritten notes and table extraction. The Paddle release sits in the same category but goes harder on three fronts that matter for large enterprises:
Hostile input conditions by default: Rather than assuming neat PDFs, the authors test directly on badly scanned, warped and photographed pages, which is far closer to how documents actually arrive in claims, risk, and operations teams.
Layout first, text second: The irregular polygon layout detection and cross‑page merging make it easier to preserve business‑relevant structure such as tables, multi‑column reports and section headings, instead of dumping a bag of text.
Compact, multi‑task design: A sub‑billion‑parameter model that can perform OCR, layout analysis, text spotting and seal recognition is much easier to deploy close to where documents live, including in constrained environments, than a 70B‑class general model.
The authors also emphasise that PaddleOCR‑VL‑1.5 can be used directly through the Transformers library, including for batch PDF processing with markdown output, which plays nicely with downstream LLMs for further analysis and summarisation.
An online demo is available to try.
For enterprises which live and breathe documents, this kind of model is an enabling piece of plumbing. In practice, the most interesting near‑term path is to test PaddleOCR‑VL‑1.5 in a narrow, well‑defined flow such as “ingest photographed claim documents into structured JSON for downstream LLM analysis”, compare it with our existing OCR stack then decide whether it forms part of a standardised document‑parsing layer. If it performs as advertised on our own data, it could quietly remove a large amount of human glue work across the organisation, which is exactly the kind of unglamorous but valuable change we want AI to deliver.

POB’s closing thoughts
Let’s wrap up this week with a few things that caught my eye!
Professor Marcel Bucher at the University of Cologne learned a painful lesson when he toggled off ChatGPT’s data consent option and instantly lost two years of work -grant applications, teaching materials, publication drafts - with no warning, no undo, and no way to get it back. His takeaway? “If a single click can irrevocably delete years of work, ChatGPT cannot be considered completely safe for professional use. These tools were not developed with academic standards of reliability and accountability in mind.” I suspect most of us wouldn't keep everything only on ChatGPT, but it's still a stark reminder of the importance of owning your data.
Andrej Karpathy just dropped a bombshell - his coding workflow completely flipped in weeks. “I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. I really am mostly programming in English now... This is easily the biggest change to my basic coding workflow in ~2 decades of programming.” The future isn’t replacing developers - it’s about making them 10x more powerful through natural language programming. The developers who get this will thrive. Those who don’t? They’ll wonder what happened.
The beautiful-mermaid launch from the Craft team is more interesting than it first appears. Mermaid diagrams have become the go-to format for AI-assisted programming because they’re text-based, version-controllable, and LLMs can both generate and interpret them naturally. What makes this tool compelling is solving the aesthetics problem (making them actually look professional) while adding terminal ASCII output for CLI environments. The broader insight: as we build AI-powered systems, we need documentation formats that work for humans, AIs, and presentations simultaneously. The convergence of developer experience and AI-native formats isn’t some future trend - it’s happening now, and teams that recognise it are building subtle but real competitive advantages. Very cool!
Thanks for reading, have a great week! 👍
I’d love to hear your feedback on whether you enjoy reading the Substack, find it useful, or if you would like to see something different in a future post. What AI topics are you most interested in for future explainers? Are there any specific AI tools or developments you'd like to see covered? Remember, if you have any questions around this Substack, AI or how Davies can help your business, you can reply to this message to reach me directly.
Finally, a reminder - while I may mention interesting new services in this post, you shouldn’t upload or enter business data into any external web service or application without ensuring it has been explicitly approved for use.
Disclaimer: The views and opinions expressed in this post are my own and do not necessarily reflect those of my employer.