
Enterprise AI Weekly #49
Don't forget about Europe, Claude Opus 4.6 is here (with fast mode), GPT-5.3-Codex puts Anthropic on notice, OpenAI Frontier focuses on agents, Bing (yes Bing) introduces AI webmaster tools.

Welcome to Enterprise AI Weekly #49
You’re reading the Enterprise AI Weekly Substack, published by me, Paul O'Brien, Group Chief AI Officer and Global Solutions CTO at Davies.
Enterprise AI Weekly is a short-ish, accessible read, covering AI topics relevant to businesses of all sizes. It aims to be an AI explainer, a route into what’s happening in AI in the world at large, and a way to understand the potential impacts of those developments on your business.
If you’re reading this for the first time, you can catch up on previous posts on the Enterprise AI Weekly Substack page. Enterprise AI Weekly is now available for anyone to sign up at https://enterpriseaiweekly.com! Please share the link and encourage others who might find it interesting to sign up.

Don’t forget about Europe!
Welcome to Enterprise AI Weekly! Before we dive into the usual US or China centric AI news, I’d like to celebrate some more European achievements!

First up, ElevenLabs, the London-founded (yes, London!) voice AI company, has raised $500 million in its Series D funding round at an $11 billion valuation, more than tripling its worth from a year ago. The company (which I’m a big fan of), closed 2025 with over $330 million in annual recurring revenue, driven by enterprise adoption from Deutsche Telekom, Square, the Ukrainian Government, and Revolut for customer support, conversational commerce, and voice agents. Led by Sequoia Capital, with A16Z and ICONIQ significantly increasing their stakes, this is one of the largest European AI funding rounds to date and marks a key moment for the UK tech ecosystem at a time when British AI companies have sometimes struggled to compete with American counterparts for capital and attention.
While the creation of the company is rooted in their voice models, ElevenLabs is also doubling down on its enterprise platform, ElevenAgents. The company announced major upgrades to its voice agents this week, enabling faster response times and improved expressiveness through turn-taking improvements and its new Eleven v3 Conversational model. The funding will also support international expansion across London, New York, San Francisco, Warsaw, Dublin, Tokyo, Seoul, Singapore, Bengaluru, Sydney, São Paulo, Berlin, Paris and Mexico City with locally embedded go-to-market teams. For those of us tracking the maturation of voice AI from novelty to genuine enterprise infrastructure, this is a validation that conversational interfaces are becoming table stakes rather than experimental features.
Staying on the European theme, Paris-based Mistral AI announced Voxtral Transcribe 2 this week, a pair of speech-to-text models that represent another statement of intent from the continent’s most prominent open-weight AI company. The release includes Voxtral Mini Transcribe V2 for batch transcription with speaker diarization, and Voxtral Realtime for low-latency streaming transcription, with the latter available as open weights under Apache 2.0. Mistral claims approximately 4% word error rate on the FLEURS benchmark whilst undercutting competitors on price at $0.003 per minute for batch processing, roughly one-fifth the cost of ElevenLabs’ Scribe v2, and processing audio three times faster whilst matching quality.

The standout feature is Voxtral Realtime’s configurable latency down to sub-200 milliseconds, which Mistral positions as critical for voice agents that need to feel conversational rather than sluggish. At 4 billion parameters, the model can run on edge devices, a significant consideration for healthcare, finance, and other regulated sectors where audio data cannot leave internal infrastructure. Both models support GDPR and HIPAA-compliant deployments, addressing the compliance concerns that have slowed enterprise AI adoption in Europe. The pricing structure creates interesting dynamics for contact centres and meeting intelligence platforms currently paying premium rates for transcription APIs. At $0.003 per minute, transcribing a million minutes of audio runs $3,000, which makes previously cost-prohibitive use cases suddenly viable.
I often forget too that Google DeepMind has deep roots in London, and with a rumoured Gemini 3.1 Pro preview release later this week, perhaps there’s more to celebrate this side of the pond than we might realise!
On with EAIW #49!

1. Claude Opus 4.6 arrives with ‘fast mode’
Anthropic has released Claude Opus 4.6, extending the model’s capabilities beyond its traditional developer stronghold into broader enterprise workflows. The model arrives with several exciting additions - agent teams in Claude Code that enable multiple AI instances to coordinate on complex tasks in parallel, a 1 million token context window for Opus-class models (matching what Sonnet 4 and 4.5 already offered), and native PowerPoint integration that puts Claude directly inside Microsoft Office. The pricing remains unchanged at $5 per million input tokens and $25 per million output tokens. On GDPval-AA, a benchmark measuring performance on economically valuable knowledge work tasks in finance and legal domains, Opus 4.6 outperforms GPT-5.2 by around 144 Elo points. The model also leads on Terminal-Bench 2.0 for agentic coding and tops Humanity’s Last Exam for multidisciplinary reasoning. Anthropic has been transparent about safety testing too, revealing that during pre-release evaluation the model autonomously discovered over 500 zero-day vulnerabilities in open-source software.
The agent teams capability in Claude Code continues a shift we’ve previously discussed from sequential execution to parallel coordination, addressing a well-known failure mode in single-agent workflows where context degrades as complexity increases. One Claude Code session acts as the team lead, breaking work into tasks, spawning teammates, assigning responsibilities and synthesising results. Teammates work independently, each with their own context window, and communicate directly with each other rather than reporting back through a hierarchy. This architectural difference matters because it enables genuine coordination - when one teammate finishes work on type definitions, they can message the UI teammate directly rather than routing through the lead. The feature is experimental and disabled by default, requiring users to add a flag to their settings.json file to enable it. Anthropic recommends starting with tasks that have clear boundaries and do not require code writing, such as reviewing pull requests, researching libraries or investigating bugs, before moving to parallel implementation work.
Agent teams work best when tasks can be properly scoped and teammates can operate largely independently. The documentation warns against two teammates editing the same file, which leads to overwrites, and suggests breaking work so each teammate owns a different set of files. The lead creates a shared task list and assigns five to six tasks per teammate to keep everyone productive and allow work to be reassigned if someone gets stuck. Users can interact with individual teammates directly without going through the lead by using keyboard shortcuts to select them, and can choose between running all teammates in a single terminal or splitting them across multiple panes. The trade-off is clear - each teammate is a full Claude Code session with its own context window, so more agents means more tokens and higher costs. The recommended pattern is to use plan mode first to create a detailed specification cheaply, then hand that plan to an agent team for parallel execution where the coordination benefit justifies the expense.

Alongside Opus 4.6, Anthropic introduced ‘fast mode’ as a research preview, which delivers 2.5 times faster output token generation for the same model at a significant price premium. Fast mode costs $30 per million input tokens and $150 per million output tokens (six times the standard rate), though there is a 50 per cent discount available until 16th February. The feature is available in Claude Code via the /fast command and through the API, but it is not supported on third-party cloud providers like AWS Bedrock, Google Vertex AI or Microsoft Azure Foundry. Fast mode uses the same Opus 4.6 model weights with a different API configuration optimised for speed rather than cost efficiency, so there is no change to intelligence or capabilities. Anthropic recommends fast mode for live debugging, rapid iteration and time-sensitive projects, but suggests sticking with standard mode for long-running autonomous tasks, batch processing and cost-sensitive workloads. Switching to fast mode mid-conversation requires paying the full fast mode rate for the entire conversation context, which makes it more expensive than enabling fast mode from the start.
For enterprises, Opus 4.6 sits at the intersection of several themes we have covered across EAIW. The 1 million token context window directly addresses context rot, the problem where conversational tools quietly forget the start of long projects. The agent teams feature reflects a pattern we have seen in vibe coding tools where explicit planning flows and parallel execution improve reliability. Upgraded PowerPoint and Excel integrations compete with Gemini in Workspace and Microsoft 365 Copilot, but rather than replacing existing ecosystems, Anthropic is positioning Claude as a tool that lives alongside them. Fast mode introduces a new dimension to the cost versus capability trade-off we explored back in EAIW #2 and #26, where we discussed how pricing for frontier models has steadily declined even as capability increased. Fast mode reverses that trend by charging a premium for speed, which may make sense for interactive development but challenges the assumption that AI workloads will always get cheaper. The discovery of 500 zero-day vulnerabilities also signals that we should expect more models capable of spotting loopholes in policies, contracts and internal rules, reinforcing the governance theme from EAIW #41where we noted that enterprises will need to treat these systems more like very fast, very literal colleagues than like simple calculators.

2. OpenAI gets serious about coding
OpenAI has released GPT-5.3-Codex, framing it as their most capable agentic coding model to date. The model merges the coding prowess of GPT-5.2-Codex with the reasoning capabilities of GPT-5.2, whilst running 25% faster than its predecessor. What sets this release apart is its capacity for sustained, autonomous work over millions of tokens, building complex applications with minimal human guidance. To demonstrate this, OpenAI showcased racing and diving games built entirely by the model through iterative development across more than 7 million tokens of work. The model achieves new benchmarks on SWE-Bench Pro and Terminal-Bench whilst using fewer tokens than competing systems, a meaningful efficiency gain for development workflows.
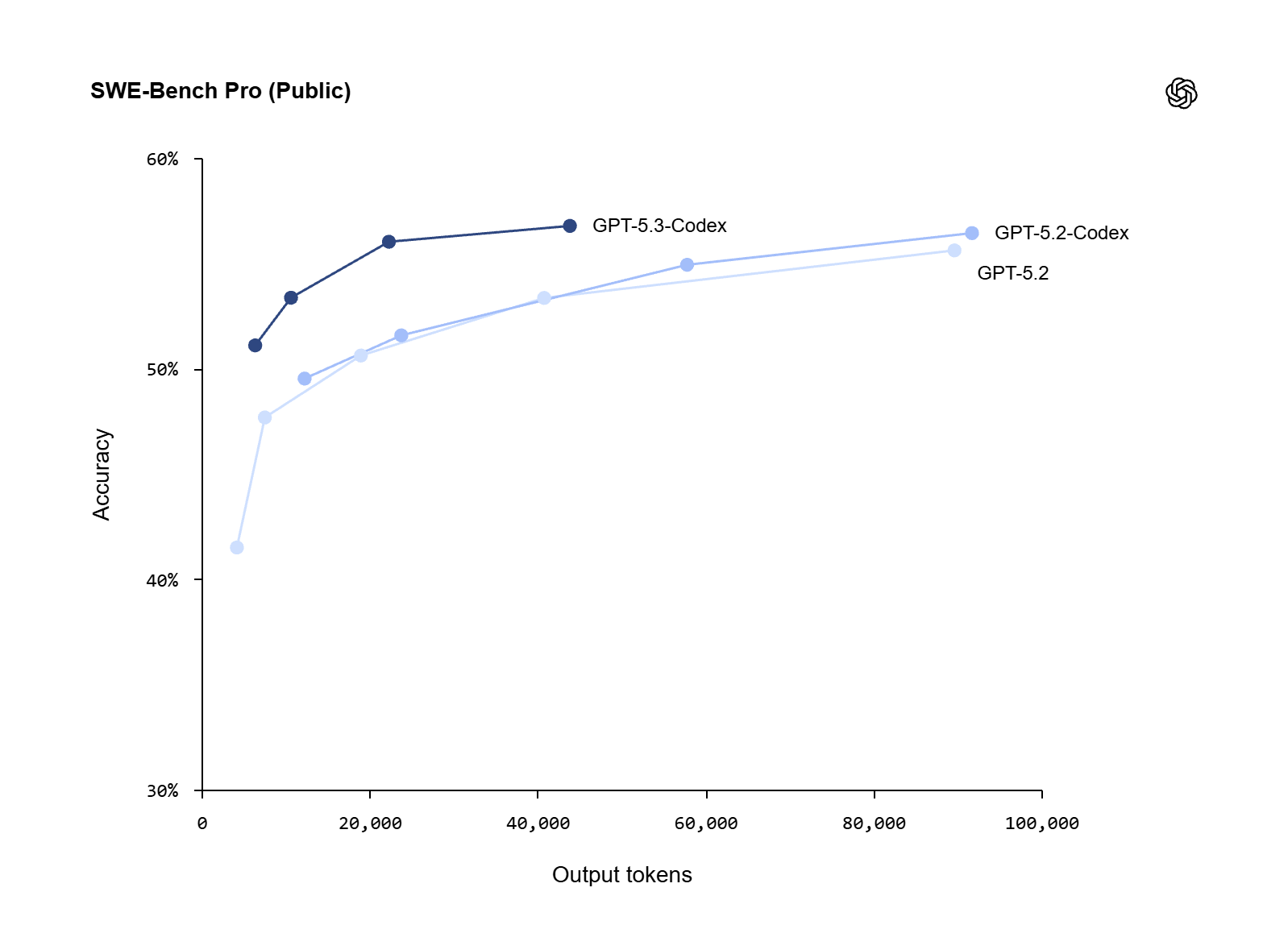
What makes GPT-5.3-Codex particularly interesting is how it was developed. OpenAI’s team used early versions of the model to debug its own training runs, manage deployments, and diagnose evaluation results. This self-improvement loop, where the model contributed to its own development, represents a tangible step towards AI systems that can meaningfully accelerate their own progress. The model extends well beyond simple code completion into territory that resembles genuine software engineering teamwork. It maintains context whilst being steered mid-task, can be delegated work asynchronously, and operates across the full development lifecycle from initial design through testing and deployment.
The launch, however, comes with a significant wrinkle. OpenAI has designated GPT-5.3-Codex as the first model to reach ‘High’ capability in cybersecurity under their Preparedness Framework. Whilst they don’t have definitive evidence the model can fully automate cyberattacks, they’re taking what they call a “precautionary approach” by deploying their most comprehensive safety stack yet. This includes safety training, automated monitoring, trusted access controls for advanced capabilities, and threat intelligence enforcement pipelines. The model’s ability to solve complex penetration testing scenarios, including binary exploitation and multi-step attack chains, has prompted OpenAI to delay full API access whilst they pilot invite-only programmes for vetted security professionals focused on defensive work. Access is instead via the Codex website or approved development tools. I’ve tried it, and it really is a step up for OpenAI, challenging the output quality of even Opus 4.6 in my experience so far.
For enterprises already navigating the agentic coding landscape we’ve tracked across previous issues (from Claude Code in EAIW #3, through the coding wars in EAIW #14, to the Codex updates in EAIW #29 and #46), GPT-5.3-Codex represents both opportunity and governance challenge. The productivity gains are substantial - faster development cycles, reduced token consumption, and the ability to delegate complex refactoring or feature builds to an autonomous agent. However, the cybersecurity classification demands that enterprises treat deployment with appropriate rigour. Access controls, code review processes, and security auditing become non-negotiable when the same capabilities that accelerate legitimate development could theoretically enable sophisticated attacks. Organisations should assess whether their existing AI governance frameworks adequately address tools that blur the line between helpful automation and potential security risk, and ensure their technical teams understand the boundaries of responsible use before widespread adoption.

3. OpenAI Frontier positions agents as digital colleagues
OpenAI has also launched Frontier, an enterprise platform designed to manage AI agents across organisations, moving beyond isolated chatbot deployments to position agents as what the company terms “AI co-workers”. The platform works with agents from OpenAI, those built internally by enterprises, and third-party offerings from providers including Google, Microsoft and Anthropic OpenAI. Early adopters include HP, Intuit, Oracle, State Farm, Thermo Fisher and Uber, whilst existing customers such as BBVA, Cisco and T-Mobile have piloted elements of the approach.

Frontier treats agents more like new employees than standalone tools, providing shared business context, onboarding processes, hands-on learning through feedback, and explicit permissions and boundaries. The platform addresses what OpenAI characterises as “agent sprawl”, where fragmented tools, siloed data and disconnected workflows reduce effectiveness. Frontier works with existing systems without forcing teams to re-platform, using open standards to integrate with current data, applications and workflows. This means agents developed in-house, acquired from OpenAI, or sourced from other vendors can operate through any interface, whether ChatGPT, Atlas, or existing business applications. Early use cases demonstrate impressive acceleration - at one manufacturer, agents reduced production optimisation work from six weeks to one day, whilst a global investment company deployed agents end-to-end across sales processes, freeing over 90% more time for customer-facing work CX Today.
The platform goes beyond technology provision. OpenAI pairs Forward Deployed Engineers with customer teams to work side by side, developing best practices for building and running agents in production whilst providing direct connection to OpenAI Research OpenAI. This consultative approach mirrors patterns we have explored previously (back in EAIW #32, we covered McKinsey’s research emphasising that value derives not simply from AI agents themselves, but from fundamentally reimagining workflows). Each agent receives its own identity with explicit permissions and guardrails, enabling confident deployment in sensitive and regulated environments, with enterprise security and governance built in OpenAI.
For enterprises, Frontier represents a maturation point in agentic AI deployment, moving from experimental pilots to production systems. The platform’s open standards approach addresses a practical challenge we have seen repeatedly - integration complexity across disparate systems and vendors. By positioning agents as manageable workforce elements rather than one-off technical implementations, OpenAI is pushing organisations to confront the workflow redesign questions that determine whether agent deployments deliver value or simply automate existing inefficiencies. The Forward Deployed Engineer model also acknowledges what many enterprises discover painfully - implementing agentic systems requires not just technology but organisational change, process mapping and continuous refinement. For those already invested in AI agent strategies, Frontier offers a framework for scaling beyond initial experiments whilst maintaining governance and control across what could otherwise become ungoverned proliferation.

4. Bing Webmaster Tools introduces AI Performance tracking
Microsoft has launched AI Performance in Bing Webmaster Tools, marking the first time publishers can systematically track how their content appears in AI-generated answers across Microsoft Copilot, Bing summaries, and partner integrations. The dashboard provides four core metrics - total citations (how often content is referenced), average cited pages (unique URLs shown as sources per day), grounding queries (the phrases AI systems used to retrieve content), and page-level citation activity. Visibility trends over time help identify patterns, whilst the grounding queries feature surfaces which search terms triggered citations, offering a window into how AI systems are actually finding and using publisher content.

This represents a step beyond traditional search analytics. Where Google Search Console shows clicks and impressions for blue links, AI Performance reveals citation patterns in generative answers, a channel that increasingly shapes how users discover information. Microsoft positions this as early-stage Generative Engine Optimisation (GEO) tooling, explicitly extending the webmaster toolkit from crawl health and search rankings into the AI answer layer. The tool respects robots.txt and other access controls, and draws on the same principles we highlighted in EAIW #20 when covering Adobe’s LLM Optimiser - monitoring agentic traffic, benchmarking visibility against competitors, and optimising content structure to improve how AI systems surface and cite information.
The recommendations Microsoft offers are practical rather than revolutionary. Strengthen domain expertise in areas already generating citations. Improve structure with clear headings, tables, and FAQ sections to make content easier for AI systems to parse accurately. Support claims with evidence and keep content current, since AI systems favour recent, well-documented information. Use IndexNow to notify search engines when content changes, ensuring AI references the latest version rather than stale snapshots. For local businesses, Bing Places complements webmaster tools by keeping location data current for AI-driven local queries. The guidance mirrors themes we explored in EAIW #5 around llms.txt and machine-readable formats - clarity, structure, and freshness matter more in AI-mediated discovery than keyword density ever did.
For enterprises, this release confirms that AI visibility is no longer speculative but measurable, and that the tooling gap between traditional SEO and GEO is closing. The dashboard’s arrival validates the shift we noted in EAIW #26, where AI referral traffic from ChatGPT grew 25.6% over two months whilst organic search rose just 5.2%. Brands that treat AI citations as an afterthought risk losing ground as generative answers become the default discovery layer. The challenge is strategic, not technical - determining which content warrants citation-focused optimisation, how to allocate resources between traditional SEO and GEO, and whether existing analytics infrastructure can absorb a new visibility metric that operates on different principles to click-through rates. Microsoft’s transparency here sets a precedent, and enterprises should expect similar tooling from Google, OpenAI, and others as the competitive dynamics of AI-mediated discovery intensify.

5. Something big is happening
This piece by Matt Shumer caught my eye this week, as a different take on how AI industry insiders are communicating with the broader public. Writing from his position as someone who has spent six years building AI startups, Shumer abandons the careful, measured tone that typically characterises tech industry commentary in favour of something far more urgent. His central thesis is straightforward - the AI capabilities that have already transformed software engineering work are about to cascade through every knowledge work profession, and the timeline is not years away but months. The essay draws heavily on personal experience, particularly his use of GPT-5.3 Codex and Claude Opus 4.6, which he describes as crossing a threshold where AI demonstrates something resembling judgement and taste rather than mere pattern matching.
What distinguishes Shumer’s argument from typical AI hype is his focus on the recursive improvement dynamic. As we noted above, OpenAI’s documentation for GPT-5.3 Codex explicitly states that the model “was instrumental in creating itself”, helping to debug its own training and manage deployment. This represents a shift from AI as a tool that humans improve to AI as an active participant in its own development cycle. Dario Amodei’s statement that AI now writes “much of the code” at Anthropic, with the feedback loop “gathering steam month by month”, reinforces this pattern. The trajectory is clear - each generation helps build the next, which is smarter, which builds the next faster, creating the conditions for what researchers call an intelligence explosion. Shumer argues this process has already started, pointing to METR’s measurements showing AI completing tasks that take human experts nearly five hours, with that capability doubling roughly every seven months and potentially accelerating to every four months.
The essay’s power comes from its framing of current events through the lens of February 2020, when early warnings about COVID-19 seemed overblown right up until they didn’t. Shumer suggests we are in an equivalent “this seems overblown” phase, but for a transformation that will be “much, much bigger than Covid”. His warning extends beyond job displacement to encompass broader societal disruption, including Amodei’s prediction that 50 per cent of entry-level white-collar jobs will be eliminated within one to five years. The specific examples span legal work, financial analysis, medical diagnosis, and customer service, but the underlying message is more universal - if your job happens on a screen, involving reading, writing, analysing, deciding or communicating through a keyboard, AI is coming for significant parts of it. The essay concludes with practical advice ranging from spending one hour daily experimenting with AI to rethinking what career advice to give children, framed not as catastrophism but as an opportunity for those who adapt early.
For enterprises, Shumer’s essay should be read as a field report from the leading edge of AI capability deployment. His observation that AI now opens applications, clicks through interfaces, tests features and iterates until satisfied mirrors exactly the computer use capabilities we covered when Google released Gemini 2.5 Computer Use. The gap between cutting-edge capability and enterprise deployment has historically been measured in years. That gap is collapsing. The recursive improvement dynamic means that capabilities demonstrated today in controlled environments will be productised and accessible far faster than previous technology waves. Businesses that wait for clear signals that AI has “arrived” will find themselves behind competitors who recognised that it already had.

POB’s closing thoughts
There’s been a lot happening in the last week (and a bit), so let’s wrap up this week with a few other things that caught my eye!
The MCP ecosystem continues its rapid expansion with the arrival of MCP Excalidraw Server, an open-source TypeScript project that transforms the popular Excalidraw drawing tool into an AI-powered visual workspace. This clever integration combines Excalidraw’s intuitive canvas with the Model Context Protocol, allowing AI assistants like Claude to create and manipulate diagrams in real time through natural language conversation.
The system operates as two independent components working in concert - a canvas server that provides the live Excalidraw interface (accessible via web browser), and an MCP server that connects AI agents to the canvas through WebSocket-based synchronisation. The result is genuinely impressive. Ask Claude to create a flowchart, system architecture diagram, or process map, and watch as elements appear instantly on your canvas, complete with proper styling, arrows, and text labels. The project supports both local and Docker deployment, offers comprehensive element management (create, update, delete, batch operations), and has recently added Mermaid diagram conversion, enabling direct transformation of Mermaid syntax into visual Excalidraw elements. Neat!
A new open-source project has distilled Andrej Karpathy’s recent observations about LLM coding pitfalls into a practical set of guidelines for improving AI-assisted development. The “Karpathy-Inspired Claude Code Guidelines” addresses core problems Karpathy identified on social media - models making wrong assumptions without checking, failing to manage confusion, overcomplicating code with bloated abstractions, and making orthogonal changes to code they don’t fully understand.
The solution arrives as a single CLAUDE.md file containing four principles that directly counter these issues. “Think Before Coding” forces explicit reasoning rather than silent assumptions, requiring the AI to state uncertainties, present multiple interpretations, and push back when warranted. “Simplicity First” combats overengineering by demanding minimum code that solves the problem with no speculative features or unnecessary abstractions. “Surgical Changes” ensures edits touch only what’s necessary, matching existing style and avoiding “improvements” to adjacent code. Finally, “Goal-Driven Execution” transforms imperative instructions into verifiable success criteria, leveraging what Karpathy identified as LLMs’ exceptional ability to loop until they meet specific goals.

Anthropic has announced a commitment to cover electricity price increases that consumers face as a result of their data centre operations, addressing one of the most contentious aspects of AI infrastructure buildout. As frontier AI model training begins to require gigawatts of power and the US AI sector needs at least 50 gigawatts of capacity over the coming years, the company is acknowledging that AI firms shouldn’t leave American ratepayers to pick up the tab for infrastructure costs.
The commitment tackles price increases through multiple mechanisms. Anthropic will pay 100 per cent of grid infrastructure costs required to interconnect their data centres, including the shares that would otherwise be passed onto consumers through monthly electricity charges. The company will work to bring net-new power generation online to match data centre electricity needs, and where new generation isn’t yet available, they’ll partner with utilities and external experts to estimate and cover demand-driven price effects. Additionally, they’re investing in curtailment systems to reduce power usage during peak demand periods and deploying grid optimisation tools to help keep prices lower for ratepayers.
Beyond financial commitments, Anthropic emphasises local community investment through job creation (hundreds of permanent positions and thousands of construction jobs from current projects), water-efficient cooling technologies, and partnerships with local leaders to share AI’s benefits more broadly. The company explicitly states these commitments apply directly where they work with partners to develop data centres for their own workloads, though they’re still exploring approaches for leased capacity from existing facilities. Importantly, they acknowledge that company-level action isn’t sufficient, supporting federal policies including permitting reform and efforts to accelerate transmission development and grid interconnection to make new energy deployment faster and cheaper for everyone. I approve.
Thanks for reading, I hope you’re having a great week! 👍
I’d love to hear your feedback on whether you enjoy reading the Substack, find it useful, or if you would like to see something different in a future post. What AI topics are you most interested in for future explainers? Are there any specific AI tools or developments you'd like to see covered? Remember, if you have any questions around this Substack, AI or how Davies can help your business, you can reply to this message to reach me directly.
Finally, a reminder - while I may mention interesting new services in this post, you shouldn’t upload or enter business data into any external web service or application without ensuring it has been explicitly approved for use.
Disclaimer: The views and opinions expressed in this post are my own and do not necessarily reflect those of my employer.