
Enterprise AI Weekly #50
Money flows into London AI, Sonnet 4.6 follows Opus, Gemini 3.1 Pro arrives, more custom silicon arrives, agents get insurance, RAM is now hot property, NotebookLM and Tesla get upgrades!

Welcome to Enterprise AI Weekly #50
You’re reading the Enterprise AI Weekly Substack, published by me, Paul O'Brien, Group Chief AI Officer and Global Solutions CTO at Davies.
Enterprise AI Weekly is a short-ish, accessible read, covering AI topics relevant to businesses of all sizes. It aims to be an AI explainer, a route into what’s happening in AI in the world at large, and a way to understand the potential impacts of those developments on your business.
If you’re reading this for the first time, you can catch up on previous posts on the Enterprise AI Weekly Substack page. Enterprise AI Weekly is now available for anyone to sign up at https://enterpriseaiweekly.com! Please share the link and encourage others who might find it interesting to sign up.

London calling, again
The pace at which major new models are arriving shows no sign of letting up. This week brings another cluster of releases and announcements from the leading labs, with capability claims escalating and the competitive pressure on enterprises to keep up with the landscape growing alongside them. Whether you find it energising or exhausting probably depends on how your AI programme is going.
Whilst much of the week’s news originates, as ever, from San Francisco, London continues to assert itself as a serious force in the global AI landscape. David Silver, one of Britain’s most accomplished AI researchers and the mind behind DeepMind’s landmark AlphaGo and AlphaStar programmes, has quietly left Google DeepMind to found a new London-based venture called Ineffable Intelligence. Yes, really. According to industry sources, he is in advanced discussions with Sequoia Capital to raise $1 billion in what would be the largest seed round ever secured by a European startup, at a reported pre-money valuation of roughly $4 billion. Sequoia partners reportedly travelled to London to meet Silver shortly after his departure, and tech giants including Nvidia, Google, and Microsoft are said to be in talks to participate. The scale of investor appetite here is striking even by the standards of a venture market that directed nearly half of all global capital last year into AI companies.
What makes Ineffable Intelligence particularly interesting is its direction of travel. Silver and computer scientist Richard Sutton published a paper last year arguing that the next meaningful leap in AI capability would not come from training on ever-larger datasets of human-generated text, but from systems that learn through experience and environmental feedback. This reinforcement learning thesis, focused on agents that refine themselves through action rather than imitation, puts Ineffable squarely in the agentic AI space that we have been tracking across recent issues. Silver remains a professor at University College London, a reminder that the UK’s deep connections between academic research and commercial application continue to produce ventures of genuine global ambition.
This development adds to a picture we have been building across recent editions. In EAIW #49 we celebrated ElevenLabs’ $500 million Series D, itself one of the largest European AI funding rounds on record. In EAIW #31, we noted the extraordinary concentration of hyperscaler investment flowing into the UK, with Microsoft, Google, and Nvidia committing tens of billions of pounds to infrastructure, research, and talent. The UK’s advantages here are not accidental - decades of world-class university research, a deep pool of talent anchored by institutions like UCL and Oxford, a regulatory environment that has generally sought to attract rather than repel investment, and the presence of DeepMind itself as a talent engine from which the next generation of founders is now emerging. Ineffable Intelligence is, in one sense, the latest chapter in that story.
Enjoy EAIW #50!

1. Sonnet 4.6 is here
Right after last week’s release of Opus 4.6, Anthropic has launched Claude Sonnet 4.6, a full upgrade of its mid-tier model that the company describes as capable of performance previously requiring its flagship Opus-class models. The release follows a familiar pattern - each new Sonnet generation absorbs capabilities that once sat exclusively at the top of the price ladder, compressing the capability gap whilst keeping costs at $3 per million input tokens and $15 per million output tokens. Early developer testing found that users preferred Sonnet 4.6 to its predecessor roughly 70% of the time in Claude Code evaluations, and, notably, preferred it to Claude Opus 4.5 in 59% of head-to-head comparisons, with testers noting fewer hallucinations, more consistent follow-through on multi-step tasks, and a markedly reduced tendency to overcomplicate solutions.

The headline addition is a substantial leap in computer use capability. When we covered Anthropic’s introduction of general-purpose computer use, the company itself acknowledged the feature was cumbersome and error-prone. Since then, successive Sonnet models have steadily improved on the OSWorld benchmark, and Sonnet 4.6 pushes the score considerably further, with early customers reporting near-human-level performance on tasks such as navigating complex spreadsheets and completing multi-step web forms. Pace, an insurance software firm, reported a 94% accuracy rate on their internal computer use benchmark, rating it the best-performing model they have tested for that capability. Alongside the computer use gains, Anthropic has extended the context window to one million tokens in beta and added improved resistance to prompt injection attacks, an issue we flagged in our coverage of Opus 4.5 as a growing concern for any workflow operating across browsers, email, and office tools.
Beyond the headline numbers, several platform-level changes accompany the release. On the API, web search and fetch tools now automatically write and execute code to filter results before passing them back to the model, reducing wasted context and improving response quality. Code execution, memory, and tool search have all moved from beta to general availability. For teams using Claude in Excel, MCP connector support now allows the model to pull data from external sources such as Bloomberg, PitchBook, and FactSet without leaving the spreadsheet, a practical expansion for financial services workflows in particular.

For enterprise buyers, the strategic significance of this release is less about the benchmark scores and more about what it does to procurement calculus. Organisations that have been reserving Opus-tier models for their most demanding workloads now have reason to reassess whether a significantly cheaper Sonnet model can carry more of that load. Databricks’ CTO noted that Sonnet 4.6 matches Opus 4.6 on OfficeQA, their benchmark for enterprise document comprehension involving charts, PDFs, and tables, which is a meaningful signal for knowledge-work deployments. The practical implication is that the cost of running document analysis, agentic coding, or computer use tasks at scale drops considerably, provided teams are willing to invest time in testing and validating which workloads can safely migrate down the model tier. Given the pace at which Anthropic has been closing the gap between its Sonnet and Opus lines, that validation work is now a worthwhile investment for any organisation running Claude at volume.

2. Google supercharges Gemini intelligence with 3.1 Pro
Google has released Gemini 3.1 Pro, the latest update to its flagship reasoning model, describing it as “a smarter, more capable baseline for complex problem-solving.” The release follows last week’s Gemini 3 Deep Think update, with Google positioning 3.1 Pro as the underlying intelligence that makes those research-grade capabilities more broadly usable. The model is rolling out in preview across the full stack - developers can access it via the Gemini API, Google AI Studio, the Gemini CLI and Antigravity, the agentic development platform we first covered in EAIW #40, enterprises can reach it through Vertex AI and Gemini Enterprise, and consumers on the AI Pro and Ultra subscription tiers will see it in the Gemini app and NotebookLM.

The headline performance claim centres on ARC-AGI-2, a benchmark designed to test how well a model handles logic patterns it has not encountered before, rather than simply recalling training data. Gemini 3.1 Pro achieved a verified score of 77.1% on this test, which Google states is more than double the score of its predecessor, 3 Pro. In practical terms, Google illustrates this with examples such as building a live aerospace dashboard from a public telemetry stream, generating complex animated SVGs from a text description, and translating literary themes into functional web design. These are not trivial demonstrations - they require the model to hold multiple layers of context, reason across domains and produce coherent, working outputs rather than plausible-sounding approximations.
It is worth noting that 3.1 Pro is launching once again in preview, not general availability, with Google explicitly citing continued validation and further work on “ambitious agentic workflows” as the reasons for the staged release. This is a prudent approach, and consistent with the broader industry trend of iterating publicly rather than waiting for perfection. The cadence of Gemini releases has accelerated markedly since we first tracked the model family back in EAIW #1, and the gap between 3 Pro and 3.1 Pro arriving in a matter of months underlines how quickly the baseline is shifting.
For enterprises evaluating or already deploying Google’s model stack, Gemini 3.1 Pro is relevant in two respects. First, its improved reasoning on novel problem structures makes it a more credible candidate for analytical workloads that involve synthesising data across formats or navigating multi-step decision chains, the kinds of tasks where previous models could feel brittle. Second, the tight integration with Vertex AI and Gemini Enterprise means that organisations already within the Google Cloud ecosystem can access this capability without significant architectural change. The preview status does counsel a measured approach to production deployment, but teams running proof-of-concept work or evaluating the model for agentic use cases would do well to begin testing now, particularly given the deep integration with Antigravity for longer-running workflow automation.

3. Is custom silicon the route to ultra-fast AI?
A startup called Taalas has been quietly making the case that the current approach to AI infrastructure is heading in the wrong direction. In a recent post titled “The Path to Ubiquitous AI,” founder Ljubisa Bajic draws a pointed parallel to ENIAC, the room-sized computing behemoth of the 1940s that was impressive in its novelty but impractical at scale. His argument is that today’s AI deployments risk the same fate: powerful on paper, but burdened by latency and cost structures that prevent genuine, widespread adoption. Taalas’s solution is total specialisation, building custom silicon for individual AI models rather than running everything through general-purpose GPU clusters. Their architecture merges storage and compute on a single chip at DRAM-level density, eliminating the fundamental bottleneck that forces today’s inference hardware to shuttle data between separate memory and compute subsystems at vastly different speeds. The result, they claim, is hardware that runs AI models an order of magnitude faster and cheaper than software-based approaches. To demonstrate that claim in practice, they’ve built ChatJimmy, a publicly accessible demo chatbot that is, frankly, unbelievably responsive. If you haven’t tried it, the experience of a large language model responding at near-instant speeds is genuinely striking, and worth a few minutes of your time.
Taalas is not the only company making this argument with silicon. We’ve tracked Cerebras across several issues of EAIW, first in EAIW #3, then again when Llama 4 Scout hit 2,600 tokens per second on their wafer-scale chips in EAIW #11, and more recently in EAIW #37 where their hardware enabled Cognition’s SWE-1.5 model to deliver 950 tokens per second in real-world coding workflows. The underlying principle is consistent - standard GPU architectures were never designed for the specific memory access patterns that transformer-based inference demands, and purpose-built alternatives can exploit that gap dramatically. This week, that theme reaches a new milestone. OpenAI has partnered with Cerebras to power a faster variant of GPT-5.3-Codex, named GPT-5.3-Codex-Spark, which runs on Cerebras’s infrastructure specifically to deliver the low-latency response times that GPU clusters struggle to sustain at scale. This is significant, not least because it signals that even the largest AI labs are beginning to accept that their own hardware stack has ceiling-level constraints for latency-critical workloads.
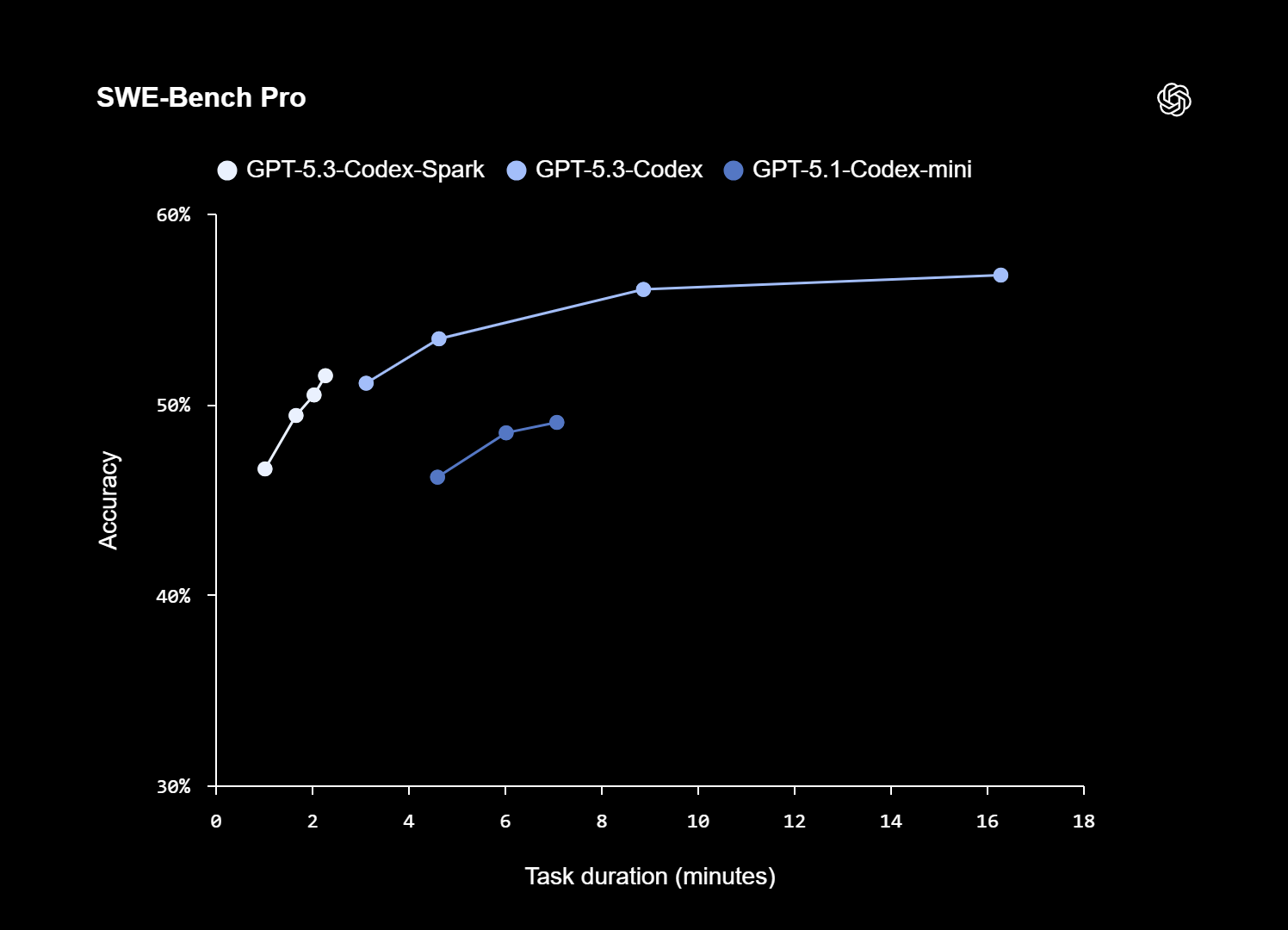
As we noted when the broader OpenAI-Cerebras partnership was announced in EAIW #46, the deal is structured to deliver 750MW of dedicated low-latency compute in tranches through 2028, a commitment that makes clear this is infrastructure planning, not a proof of concept. The Taalas argument and the Cerebras model converge on the same conclusion - general-purpose compute, whether NVIDIA GPUs or cloud CPUs, will remain the workhorse of AI training and batch inference, but it is structurally unsuited to the sub-second response times that the most valuable enterprise AI applications require. Voice agents, real-time coding assistants, live customer interactions, and autonomous decision loops all share a common constraint. They cannot tolerate the kind of latency that feels acceptable in a chat window but is fatal in a production workflow.
For enterprise teams evaluating their AI deployment stack, this should reframe a question that is often asked too narrowly. The conversation about AI infrastructure tends to focus on cost per token, model capability, and vendor lock-in risk. Speed, as a distinct dimension of value, is underweighted, particularly because most current AI deployments are asynchronous enough that a two-second response feels fine. That calculus shifts significantly once you move into agentic workflows, where models are calling tools, receiving results, and making decisions in loops that compound across dozens of steps. At that point, the difference between 40 tokens per second and 2,600 tokens per second is not a marginal improvement in user experience but a qualitative change in what the system can accomplish within a meaningful time window. Whether the route to that speed is via Cerebras partnerships, Taalas-style custom silicon, or the next generation of inference-optimised hardware from established cloud providers, the direction of travel is clear - speed is becoming a first-class requirement, and organisations that treat it as an afterthought in their AI architecture decisions may find themselves rebuilding sooner than they expect.

4. ElevenLabs secures first AI agent insurance
ElevenLabs has taken what may be a genuinely significant step in the maturation of enterprise AI deployment, becoming the first company to secure an insurance policy covering AI voice agents through AIUC-1 certification from the Artificial Intelligence Underwriting Company (AIUC). The announcement, coming hot on the heels of the company’s $500 million Series D and $11 billion valuation we covered last week, signals that ElevenLabs is thinking well beyond model capability. Its ElevenAgents platform now powers over three million voice agents globally, used by employees at more than 75% of Fortune 500 companies including Cisco, Revolut, and MasterClass. The ability to insure those agents and their actions represents a notable shift in how AI systems can be positioned within corporate risk frameworks.

The AIUC-1 certification at the heart of this announcement is not a paper exercise. ElevenLabs’ agents underwent 5,835 technical tests across 14 risk categories, including adversarial simulations modelled on documented real-world AI failures such as hallucinations, prompt injection attacks, and data leakage. The process generates empirical risk profiles of the kind that traditional insurers require before underwriting any technology, and it builds on ElevenLabs’ existing safety architecture, which layers pre-production red teaming, real-time moderation, and ongoing automated monitoring. The company has also made its AI Audio Classifier publicly available, allowing anyone to verify whether a given audio clip was generated on its platform. Certification is not a one-time badge - it reflects a documented, testable standard of robustness.
For existing ElevenAgents customers, the practical pathway to certification is reportedly faster than it might sound. Because the platform’s built-in safety controls already satisfy a significant portion of the AIUC-1 requirements, customers are described as being up to 75% of the way towards certification before any additional work begins. ElevenLabs cites a customer who achieved full certification in four weeks, with an agent handling property enquiries around the clock. That speed matters commercially, since lengthy compliance cycles are one of the most common reasons enterprises stall on moving AI pilots into production.
For enterprise leaders, this development is worth watching beyond any affinity for ElevenLabs specifically. The broader question it raises is whether insurance-backed certification could become a standard expectation for enterprise-grade AI agents, much as SOC 2 or ISO 27001 compliance became baseline requirements for cloud software vendors over the past decade. Organisations currently wrestling with board-level questions about AI accountability now have a concrete, third-party-validated framework to point to. It also shifts the conversation about AI risk from the abstract to the actuarial: if a voice agent provides incorrect information to a customer and causes measurable harm, there is now a mechanism for financial recourse. That is a meaningful development for any organisation deploying AI in regulated industries, customer-facing roles, or anywhere the consequences of an error carry real weight.

5. Get ready for the big RAM shortage
The term “RAMageddon” has moved from tech forum speculation to boardroom concern with remarkable speed. What began as a structural reallocation of semiconductor manufacturing capacity is now causing measurable harm to enterprises, consumers, and hardware vendors alike. The root cause is relatively straightforward: Samsung, SK Hynix, and Micron - the three manufacturers who between them control roughly 95% of global DRAM production - have pivoted their limited cleanroom capacity towards High Bandwidth Memory (HBM) for AI accelerators and data centre GPUs. This is, in IDC’s assessment, a zero-sum game: every wafer allocated to an HBM stack for an Nvidia GPU is a wafer denied to the LPDDR5X module of a mid-range smartphone or the SSD of a consumer laptop. The consequences are already visible in pricing - DRAM prices reportedly rose 172% throughout 2025, leading Samsung to halt new orders for DDR5 modules to reassess pricing structures and Micron to exit its Crucial brand of consumer products entirely.
The scale of disruption is becoming impossible to ignore at the executive level. A growing number of tech industry leaders, including Tim Cook and Elon Musk, have warned about the severity of the shortage since the start of 2026, with Micron calling the bottleneck “unprecedented” and Musk declaring that Tesla may need to build its own memory fabrication plant. On the supply side, Samsung has told OEM customers there is simply “no stock” available, and contract prices for DDR5 RAM have risen by more than 100%, from around $7 per unit earlier this year to $19.50. The shortage is not expected to be short-lived either. Micron has stated the RAM shortage will last until at least 2028, or until AI demand starts to abate. For anyone hoping this resolves itself quietly before the next refresh cycle, the outlook is bleak.
The timing could scarcely be worse for the PC market specifically. The memory shortage creates a perfect storm for the PC industry, colliding simultaneously with the Windows 10 end-of-life refresh cycle and the AI PC marketing push - a moment when the industry is encouraging users to adopt devices with more RAM, precisely as RAM becomes prohibitively expensive to include. Major OEMs are already warning of significant price hikes. Lenovo, Dell, HP, Acer, and ASUS have signalled 15 to 20% PC price increases for 2026 due to DRAM and NAND shortages, with some forecasts pointing to increases as high as 30%. We noted in EAIW #35 the already uncomfortable pricing of Apple’s higher-memory MacBook configurations, that situation is not improving. Some manufacturers are responding by reducing baseline specifications rather than absorbing costs, with reports of new laptops shipping with just 8GB of RAM.
For enterprises, this is a hardware planning problem that deserves attention now rather than at the point of purchase. Procurement teams that were already planning device refresh programmes - particularly those tied to the Windows 10 end-of-life deadline - face a difficult calculation: move quickly and pay elevated prices, or delay and risk paying even more. Industry experts are recommending buying strategically now, as DRAM and SSD prices are already rising and further increases are expected through 2026. Organisations that have been evaluating AI PCs - devices that typically require 16GB or more to run local models effectively - may find that premium now significantly higher than modelled. IT leaders should revisit device lifecycle assumptions, consider extending the life of existing hardware where possible, and factor memory pricing volatility into any AI deployment roadmaps that assume on-device inference capability. The AI infrastructure boom that enterprises are investing in is, rather ironically, making the endpoint hardware those enterprises rely on more expensive to refresh.

POB’s closing thoughts
Let’s wrap up this week with a few things that caught my eye!
Regular readers will know I’m a long-standing admirer of Google’s NotebookLM, and this week it has delivered on what users have been asking for most. Two new features are rolling out now - prompt-based slide revisions, which allow you to tweak and refine your presentations simply by describing the changes you want in natural language, and PPTX export, enabling you to download your AI-generated slide decks as standard PowerPoint files. Google Slides export is confirmed as the next step. We’ve tracked NotebookLM’s evolution through numerous issues, from the expanded file type support covered in EAIW #39, to the MCP server integration in EAIW #46 that opened up programmatic access from coding assistants. This latest update closes what was arguably the most important remaining gap in its content creation workflow, making the output genuinely portable for the first time.

The prompt-based revision capability is the more transformative of the two additions. Previously, iterating on a NotebookLM slide deck required working within its own interface constraints. Now you can guide revisions conversationally, which aligns the tool much more closely with how people actually think about refining a presentation. Combined with PPTX export, this means a knowledge base can now travel all the way from uploaded documents to a polished, editable deck ready for use in a standard enterprise environment, without manual reformatting.
At last, xAI’s Grok assistant is rolling out to Tesla vehicles across Europe, initially covering the UK, Ireland, Germany, Switzerland, Austria, Italy, France, Portugal, and Spain, with further markets to follow. The integration allows Grok to answer questions using real-time information and to add or edit navigation destinations, positioning it as a conversational co-pilot for drivers. We covered the original announcement of Grok’s planned Tesla integration in EAIW #21, when Musk indicated it was imminent, and this European rollout represents that promise finally materialising at scale outside North America.
The pairing of Grok with Tesla’s in-car interface is a logical fit given the shared ownership and the fact that Tesla’s vehicles already support a capable voice and touchscreen interface. Adding a model with live web access changes the character of those interactions significantly, moving beyond navigation and media controls towards something closer to a general-purpose assistant that happens to be sitting in your dashboard. Whether that’s genuinely useful on a regular commute or a motorway run is a reasonable question, but for longer journeys the case for a knowledgeable, conversational assistant with real-time information becomes more compelling.
Thanks for reading, I hope you’re having a great weekend! 👍
I’d love to hear your feedback on whether you enjoy reading the Substack, find it useful, or if you would like to see something different in a future post. What AI topics are you most interested in for future explainers? Are there any specific AI tools or developments you'd like to see covered? Remember, if you have any questions around this Substack, AI or how Davies can help your business, you can reply to this message to reach me directly.
Finally, a reminder - while I may mention interesting new services in this post, you shouldn’t upload or enter business data into any external web service or application without ensuring it has been explicitly approved for use.
Disclaimer: The views and opinions expressed in this post are my own and do not necessarily reflect those of my employer.